C#/ VB.NET中怎么从PDF文档中提取所有表格
导读:本文共2277字符,通常情况下阅读需要8分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 这篇文章主要介绍了C#/ VB.NET中怎么从PDF文档中提取所有表格的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇C#/ VB.NET中怎么从PDF文档中提取所有表格文章都会有所收获,下面我们一起来看看吧。安装首先,我们需要将 Spire.PDF for... ...
音频解说
目录
(为您整理了一些要点),点击可以直达。
这篇文章主要介绍了C#/ VB.NET中怎么从PDF文档中提取所有表格的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇C#/ VB.NET中怎么从PDF文档中提取所有表格文章都会有所收获,下面我们一起来看看吧。
安装
首先,我们需要将 Spire.PDF for .NET 包中包含的 DLL 文件添加为 .NET 项目中的引用。可以从此链接下载 DLL 文件,也可以通过NuGet安装 DLL 文件。
PM> Install-Package Spire.PDF
从PDF文档中提取表格
Spire.PDF提供了PdfTableExtractor.ExtractTable()方法,用于从特定页面中提取表格。以下是从整个PDF文档中提取表格的详细步骤。
创建一个Document类的对象,并加载源 PDF 文件。
遍历文档中的页面,并使用ExtractTable()方法从特定页面获取表格列表。
遍历特定表格中的单元格,并通过PdfTable.GetText()方法获取单元格值。
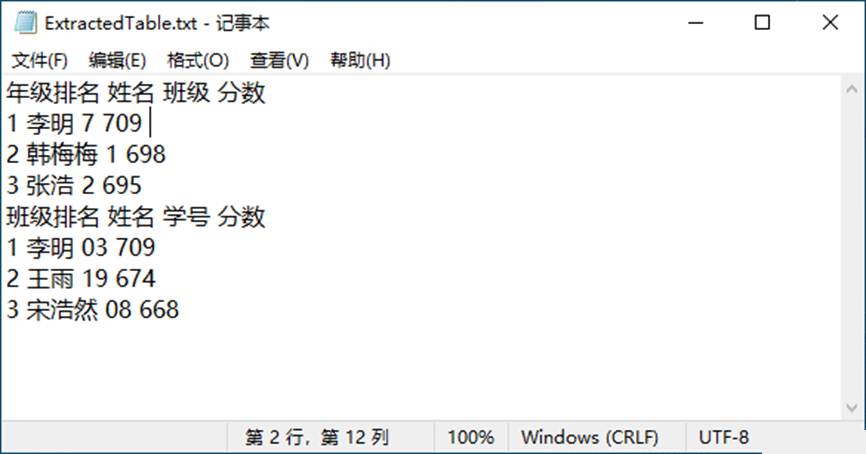
将所提取的数据写入 TXT 文件。
[C#]
usingSpire.Pdf;usingSpire.Pdf.Utilities;usingSystem.IO;usingSystem.Text;namespaceExtractTable{classProgram{staticvoidMain(string[]args){//实例化PdfDocument类的对象PdfDocumentpdf=newPdfDocument();//加载PDF文档pdf.LoadFromFile("sample.pdf");//创建StringBuilder类的对象StringBuilderbuilder=newStringBuilder();//实例化PdfTableExtractor类的对象PdfTableExtractorextractor=newPdfTableExtractor(pdf);//声明一个PdfTable类的表格数组PdfTable[]tableLists;//遍历PDF页面for(intpageIndex=0;pageIndex<pdf.Pages.Count;pageIndex++){//从页面提取表格tableLists=extractor.ExtractTable(pageIndex);//判断表格列表是否为空if(tableLists!=null&&tableLists.Length>0){//遍历表格foreach(PdfTabletableintableLists){//获取表格中的行和列数introw=table.GetRowCount();intcolumn=table.GetColumnCount();//遍历表格行和列for(inti=0;i<row;i++){for(intj=0;j<column;j++){//获取行和列中的文本stringtext=table.GetText(i,j);//写入文本到StringBuilder容器builder.Append(text+"");}builder.Append("\r\n");}}}}//保存提取的表格内容为.txt文档File.WriteAllText("ExtractedTable.txt",builder.ToString());}}VB.NET
ImportsSpire.PdfImportsSpire.Pdf.UtilitiesImportsSystem.IOImportsSystem.TextNamespaceExtractTableClassProgramPrivateSharedSubMain(argsAsString())'实例化PdfDocument类的对象DimpdfAsNewPdfDocument()'加载PDF文档pdf.LoadFromFile("sample.pdf")'创建StringBuilder类的对象DimbuilderAsNewStringBuilder()'实例化PdfTableExtractor类的对象DimextractorAsNewPdfTableExtractor(pdf)'声明一个PdfTable类的表格数组DimtableListsAsPdfTable()'遍历PDF页面ForpageIndexAsInteger=0Topdf.Pages.Count-1'从页面提取表格tableLists=extractor.ExtractTable(pageIndex)'判断表格列表是否为空IftableListsIsNotNothingAndAlsotableLists.Length>0Then'遍历表格ForEachtableAsPdfTableIntableLists'获取表格中的行和列数DimrowAsInteger=table.GetRowCount()DimcolumnAsInteger=table.GetColumnCount()'遍历表格行和列ForiAsInteger=0Torow-1ForjAsInteger=0Tocolumn-1'获取行和列中的文本DimtextAsString=table.GetText(i,j)'写入文本到StringBuilder容器builder.Append(text&Convert.ToString(""))Nextbuilder.Append(vbCr&vbLf)NextNextEndIfNext'保存提取的表格内容为.txt文档File.WriteAllText("ExtractedTable.txt",builder.ToString())EndSubEndClassEndNamespace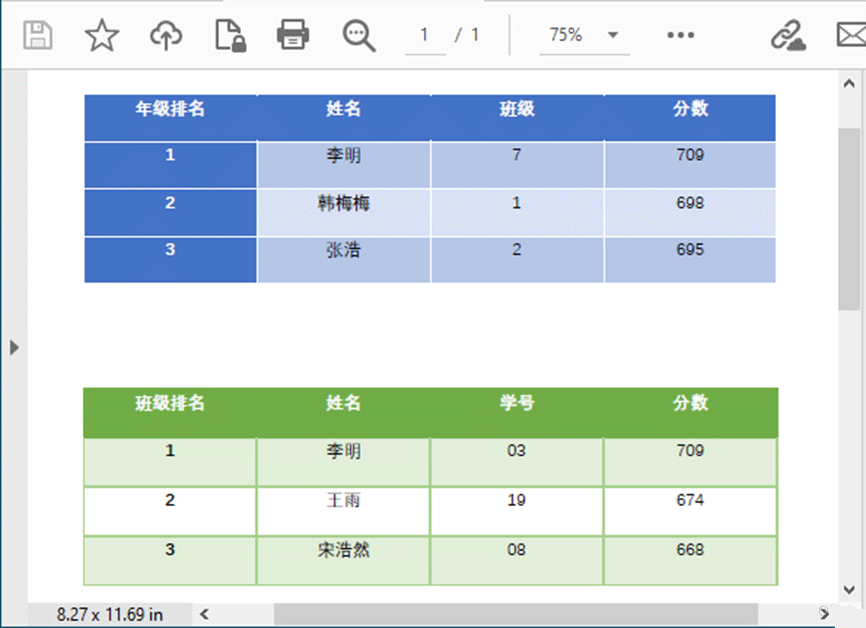
本文:
C#/ VB.NET中怎么从PDF文档中提取所有表格的详细内容,希望对您有所帮助,信息来源于网络。