C语言数据在内存中是怎样存储的
导读:本文共2533.5字符,通常情况下阅读需要8分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 数据类型详细介绍在前面C语言基础概览中,已经提到过了基本的C语言内置类型,但C语言的数据类型有无数种~ 但是可以把这些类型分为几个大类:类型的归类:存整数的char,short,int,long,long long及所配套的unsigned,int*,int[]…2.存浮点数的float,double,float[]…结构体(结构体在内存中的存储后面在进行讨论~... ...
目录
(为您整理了一些要点),点击可以直达。数据类型详细介绍
在前面C语言基础概览中,已经提到过了基本的C语言内置类型,但C语言的数据类型有无数种~ 但是可以把这些类型分为几个大类:
类型的归类:
存整数的
char,short,int,long,long long及所配套的unsigned,int*,int[]…2.存浮点数的
float,double,float[]…结构体(结构体在内存中的存储后面在进行讨论~)
整数在内存种的存储:
1.字节序
2.补码
内存窗口
调试模式下的内存窗口,若不是调试状态,是打不开内存窗口的,正常情况下,不调试,是没有内存窗口的

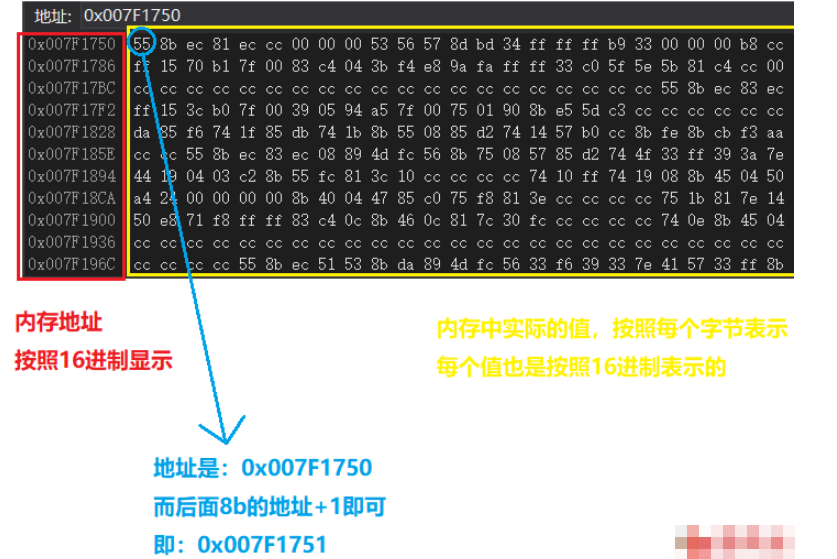
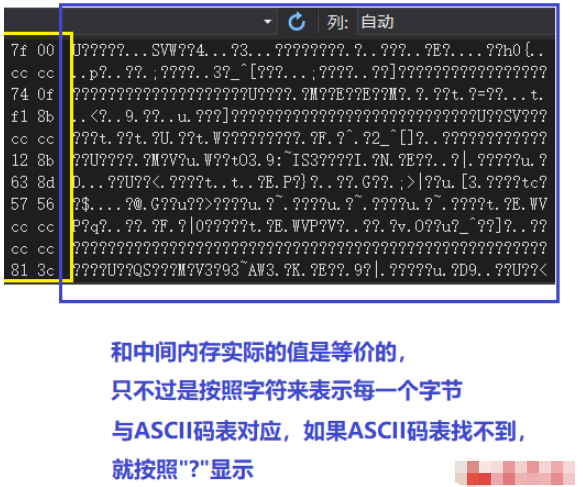
charstr[]="abc";
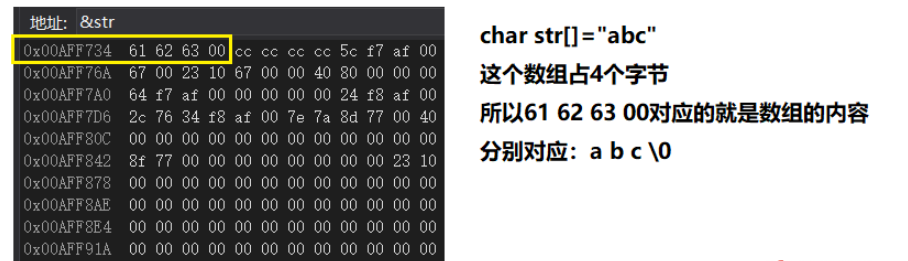
这里内存数据只截了部分图,方便清晰观察
内存数据中有很多的"cc cc cc",就是0xcc,其实在Intel的CPU中表示中断指令,VS的debug模式下,会把局部变量的后边填充上0xcc,填充的目的是及时发现下标越界
intnum=0x11223344;

此处就涉及到字节序
字节序
字节序是以字节为单位
字节序分为大端字节序(大端序)和小端字节序(小端序)
大端字节序:就是把地位放在高地址上
小端字节序:就是把低位(小)放在低地址(小)上(小小小)
总的来说,小端序的应用更广泛。字节序是和CPU相关的属性,Intel的CPU主要都是小端序~
上述例子:0x11223344 内存数据若是11223344,则为大端序,44332211则为小端序。
程序判断大端序or小端序?
intisBidEnd(){ intnum=0x11223344; int*p=# char*p2=(char*)p; if(*p2==0x11){ return1; } else{ return0; }}intmain(){ intret=isBidEnd(); if(ret==1){ printf("是大端序\n"); } else{ printf("是小端序\n"); } system("pause"); return0;}指针之间的强制类型转换,不会影响指针内部存储的地址值,只影响后序的解引用操作~
网络传输的字节序固定使用大端~
补码
整形在内存中的存储:原码、反码、补码
原码:在正数的二进制基础上,把符号位设为1
反码:符号位不变,其他位取反~
补码:反码+1,即可得到补码
正数的原码、反码和补码都相同
举例:
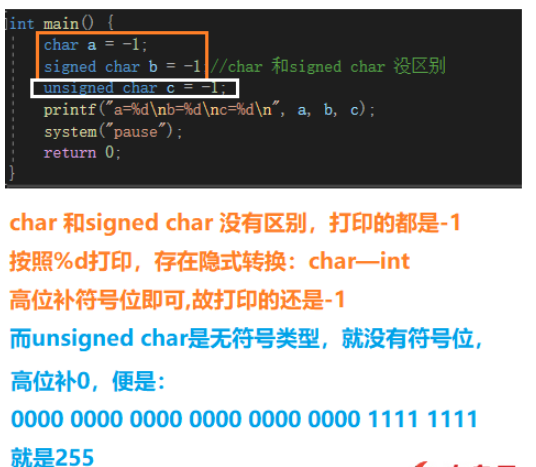
intmain(){chara=-1;signedcharb=-1;//char和signedchar没区别unsignedcharc=-1;printf("a=%d\nb=%d\nc=%d\n",a,b,c);system("pause");return0;}类型转换的规则
1.把长的数据转换成短的数据,高位直接"截断"
2.把短的数据转为成长的数据,高位要补符号位
浮点型在内存中的存储
小数在计算机中的计算要比整数复杂很多~
浮点数储存规则:
IEEE754规定:
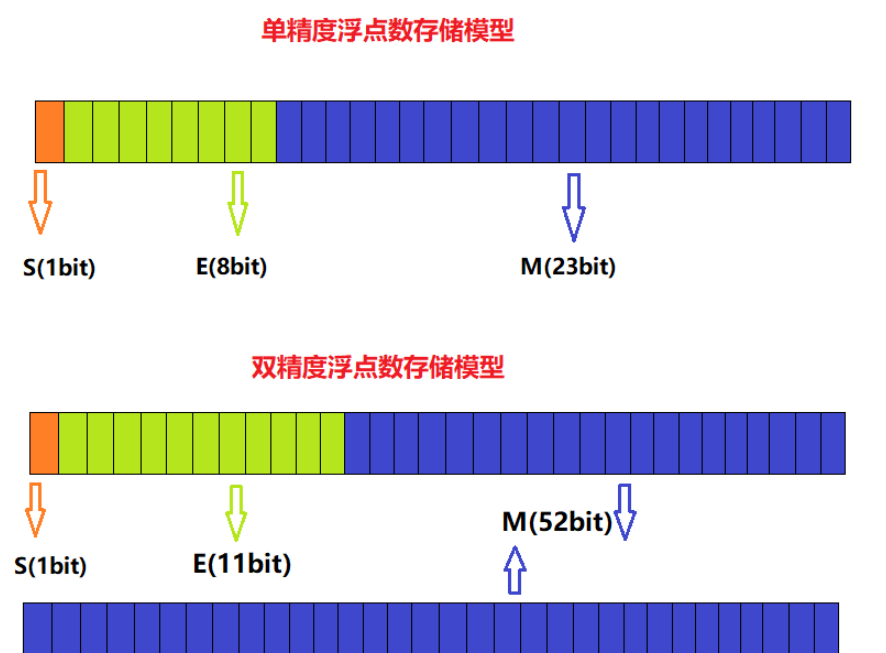
对于32位的浮点数:
最高的一位是符号位s,接着的8位是指数E,剩下的23位为有效数字M
对于64位的浮点数:
最高的一位是符号位S,接着的11位是指数E,剩下的52位为有效数组M
一个浮点数在计算机里是运用"科学计数法"的方式来表示的~用2的多少次方来表示
2^E (2的E次方)
E越大,能表示的数据范围就越大
M越大,能表示的数据的精度就越高
因此优先考虑使用double
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">C语言数据在内存中是怎样存储的的详细内容,希望对您有所帮助,信息来源于网络。