MySQL表数据操作实例分析
导读:本文共12041字符,通常情况下阅读需要40分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要:这篇文章主要介绍“MySQL表数据操作实例分析”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“MySQL表数据操作实例分析”文章能帮助大家解决问题。正式开始操作之前,我们先来聊一聊它们的关键字:INSERTSELECTUPDATEDELETE大家可以先通过help命令来查看一下相关的语法,提前预习一下,方便更深的理解正式上菜先来看看之前的表结构:create... ...
目录
(为您整理了一些要点),点击可以直达。这篇文章主要介绍“MySQL表数据操作实例分析”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“MySQL表数据操作实例分析”文章能帮助大家解决问题。
正式开始操作之前,我们先来聊一聊它们的关键字:
INSERT
SELECT
UPDATE
DELETE
大家可以先通过help命令来查看一下相关的语法,提前预习一下,方便更深的理解
正式上菜
先来看看之前的表结构:
createtableifnotexiststb_user(idbigintprimarykeyauto_incrementcomment'主键',login_namevarchar(48)comment'登录账户',login_pwdchar(36)comment'登录密码',accountdecimal(20,8)comment'账户余额',login_ipintcomment'登录IP')charset=utf8mb4engine=InnoDBcomment'用户表';
插入数据
在插入之前,我们先来看看平常怎么使用的
insertintotable_name[(column_name[,column_name]...)]value|values(value_list)[,(value_list)]
其实最常用的就这么多,下面我们来举个例子就明白了
全部字段插入单条数据
insertintotb_uservalue(1,'admiun','abc123456',2000,inet_aton('127.0.0.1'));这样就插入了一条数据:
auto_increment:自增键,在插入数据的时候可以不给当前列指定数据,而且默认情况下我们推荐给主键设置自增inet_aton:ip转换函数,相对应的还有inet_ntoa()
而且还需要注意一点,如果存在相同的主键,那么在插入的时候会出现错误
#主键已重复Duplicateentry'4'forkey'tb_user.PRIMARY'
指定字段插入多条数据
insertintotb_user(login_name,login_pwd)values('admin1','abc123456'),('admin2','abc123456')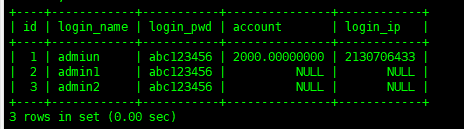
可以看到数据已经插入进来,没有填充数据的列已NULL填充,关于这一点,我们可以在创建表的时候通过DEFAULT来指定默认值,就是在这个时候使用的
altertabletb_useraddcolumnemailvarchar(50)default'test@sina.com'comment'邮箱'
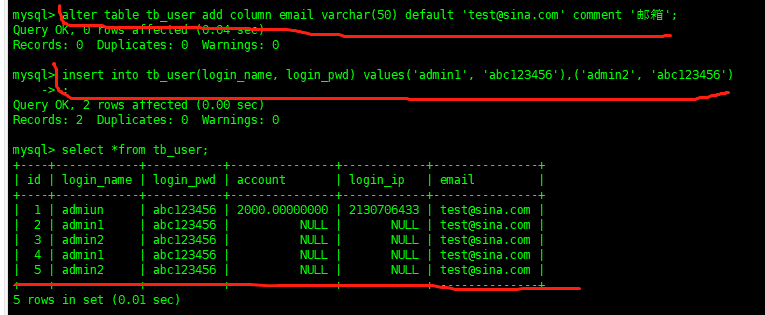
没有什么比实际动手有说服力的了
ON DUPLICATE KEY UPDATE
这里还有一个点,用到的不是很多,但是相当实用:ON DUPLICATE KEY UPDATE
也就是说如果数据表中存在重复的主键,那么就进行更新操作,来看:
insertintotb_user(id,login_name,email)value(4,'test','super@sina.com')onduplicatekeyupdatelogin_name=values(login_name),email=values(email);

对比上面的数据,很容易就会发现数据不一样了
values(列名): 会取出前面插入的字段的数据
insertintotb_user(id,login_name,email)values(4,'test','super@sina.com'),(5,'test5','test5@sinacom')onduplicatekeyupdatelogin_name=values(login_name),email=values(email);
插入多条数据也是一样的,就不贴图了,大家自己动手试一下
修改数据
插入数据相对而言比较简单,下面我们来看看修改数据
首先从update语法上来讲,这个更简单:
updatetable_namesetcolumn_name=value_list(,column_name=value_list)wherecondition
举个栗子:
updatetb_usersetlogin_name='super@sina.com'whereid=1
这样就修改了tb_user下编号为1的loign_name的数据
where后条件也可以多个,按照,分割
当然,如果没有设置查询条件的话,那么默认是会修改整张表的数据
updatetb_usersetlogin_name='super@sina.com',account=2000
好了,修改数据到这里就结束了,很简单
删除数据
删除数据分为:
删除指定数据
清空整张表
如果只是想删除某些数据,可以通过delete来删除,还是来举个栗子:
deletefromtb_userwherelogin_ipisnull;
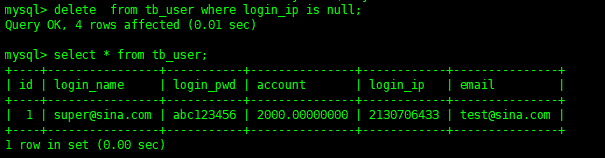
这样就删除了指定条件的数据
那么,如果我们执行删除条件,但是不设置条件呢?下面我们来看一看
先执行
insert操作插入几条数据
deletefromtb_user;
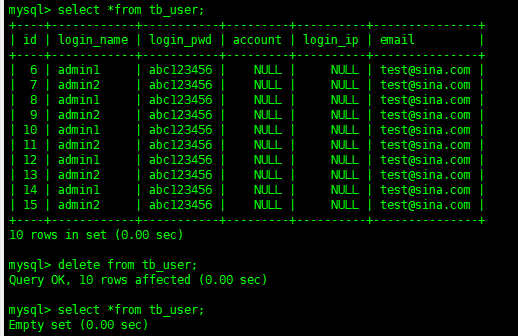
可以看到,删除了全部的数据
但其实还有一种方式可以清空整张表,就是通过truncate的方式,这种方式的效率更高
truncatetb_user;
最后就不贴图了,肯定没问题的
查询数据
查询数据分为多种情况,组合使用可以有N中存在,所以说这是最复杂的一种方式,下面我们一一来介绍
其实如果从语法上来看:查询语法关键点只会包含如下几点:
SELECT [DISTINCT]select_expr[,select_expr]FROMtable_nameWHEREwhere_conditionGROUPBYcol_nameHAVINGwhere_conditionORDERBYcol_nameASC|DESCLIMIToffset[,row_count]
记住这些关键点,查询就相当简单了,下面我们先来看个简单的操作
简单查询
select*fromtb_user;--按照指定字段排序asc:正序desc:倒序select*fromtb_userorderbyiddesc;
一共插入了44条数据,没有全部截图
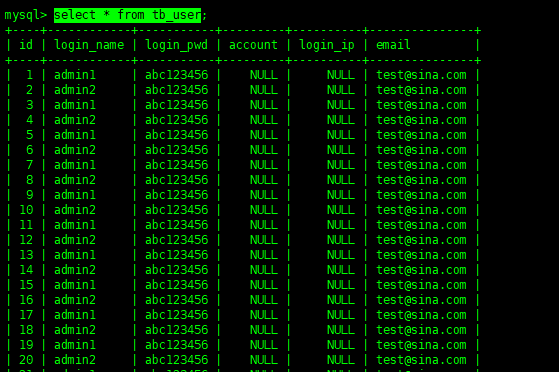
当前SQL会查询出表中全部数据,而跟在select后面的*表示:列出全部的字段,如果我们只是想列出某些列的话,那么将它换成指定的字段名就好:
selectid,login_name,login_pwdfromtb_user;
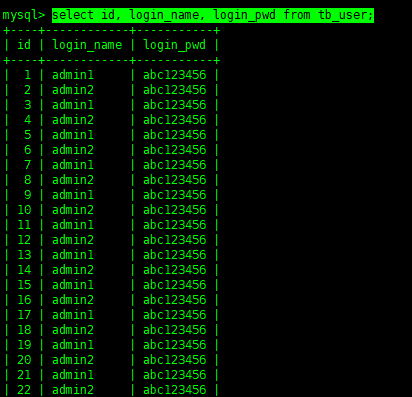
就是这么简单
当然了,还记得这个关键字么:DISTINCT,我们来实验一下:
selectdistinctlogin_namefromtb_user;
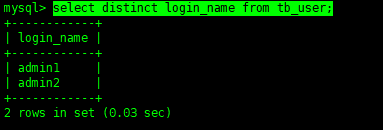
意思已经很明显了,没错,就是去重操作。
但是我要告诉大家的是,distinct关键字如果作用在多个字段的话,那么只有在多个字段组合的情况下重复才会进行生效,举个栗子:
selectdistinctid,login_namefromtb_user;
只有在 id + login_name有重复的时候会生效
聚合函数
在MySQL中内置的聚合函数,对一组数据执行计算,并返回单条值,在特殊场景下有特殊的作用
可以加where条件
--查询当前表中的数据条数selectcount(*)fromtb_user;--查询当前表中指定列最大的一条selectmax(id)fromtb_user;--查询当前表中指定列最小的一条selectmin(id)fromtb_user;--查询当前表中指定列的平均值selectavg(account)fromtb_user;--查询当前表中指定列的总和selectsum(account)fromtb_user;
除了聚合函数之外,还包含很多普通函数,这里就不一一列举了,给出官方文档,用的时候具体查
条件查询
看到了第一个例子是不是感觉其实查询没有那么难。上面的例子都是查询出全部数据,下面我们要加一些条件进行筛选,这里就用到了我们的where语句,记住一点:
条件筛选是可以有多个的
等值查询
我们可以通过如下方式进行条件判断
select*fromtb_userwherelogin_name='admin1'andlogin_pwd='abc123456';
很多情况下,column_name = column_value是我们用到更多的查询方式,这种方式我们可以称为等值查询,
而且注意到,在条件之前我是通过and来进行关联的,Java基础不错的小伙伴肯定也记得&&,都是表示并且的意
既然有and,那么与之相反的肯定就是or了,表示只要两者满足其中一条就好
select*fromtb_userwherelogin_name='admin1'orlogin_pwd='abc123456';
除了=匹配的方式,还有其他更多的方式,<,<=,>,>=
和我们认知中不一样的是:
<>表示不等于
不过这些使用方式都是一样的
批量查询
在某些特定的情况下,如果想要查询出一批数据,可以通过in来进行查询
select*fromtb_userwhereidin(1,2,3,4,5,6);
在in中,相当于传入的是一个集合,然后查询指定集合的数据,在很多情况下,这条sql还可以这么写
select*fromtb_userwhereidin( selectidfromtb_userwherelogin_name='admin1');
除了in,还有not in与之相反:表示要查询出来的不包含这些指定的数据
模糊查询
看完了等值查询,我们再来看一个模糊查询:
只要字段数据中包含查询的数据,就能够匹配到数据
select*fromtb_userwherelogin_namelike'%admin%';select*fromtb_userwherelogin_namelike'%admin';select*fromtb_userwherelogin_namelike'admin%';
like就是我们模糊查询中的关键成员,而后面的查询关键字分为三种情况:
%admin%:%夹着查询关键字表示只要数据中包含
admin就能匹配到%admin: 任意关键字开头,只要是admin结尾的数据都能匹配到
admin%:必须是admin开头,其他的随意,这样的数据就能匹配到
更多的推荐采用这种方式,如果查询列设置了索引的话,其他方式会让索引失效
非空判断
查询当前表会发现,数据中的某些列是NULL值,如果我们在查询过程中向要过滤掉这些数据,我们可以这么做:
select*fromtb_userwhereaccountisnotnull;select*fromtb_userwhereaccountisnull;
is not null就是其中的关键点,与之相对的还有is null,意思正好相反
时间判断
很多情况下,如果我们想要通过时间段来匹配查询,那么我们可以这样做:
tb_user表没有时间字段,这里添加了一个字段:create_time
select*fromtb_userwherecreate_timebetween'2021-04-0100:00:00'andnow();
**now()**函数表示当前时间
between之后表示开始时间,and之后表示结束时间
行转列
我从一个面试题来聊一聊这个查询吧:
场景是一样的,但是SQL不一样 (关注重点,看题)
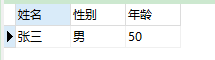
createtabletest(idint(10)primarykey,typeint(10),t_idint(10),valuevarchar(5));insertintotestvalues(100,1,1,'张三');insertintotestvalues(200,2,1,'男');insertintotestvalues(300,3,1,'50');insertintotestvalues(101,1,2,'刘二');insertintotestvalues(201,2,2,'男');insertintotestvalues(301,3,2,'30');insertintotestvalues(102,1,3,'刘三');insertintotestvalues(202,2,3,'女');insertintotestvalues(302,3,3,'10');
请写出一条SQL展示如下结果:
姓名 性别 年龄
--------- -------- ----
张三 男 50
刘二 男 30
刘三 女 10
对比常规查询,可以说我们需要重新定义新的属性列来展示,所以需要需要通过判断来完成属性列的转换
case
先一步一步的来,既然需要判断,那么就通过case .. when .. then .. else .. end来
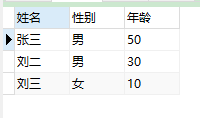
SELECT CASEtypeWHEN1THENvalueEND'姓名', CASEtypeWHEN2THENvalueEND'性别', CASEtypeWHEN3THENvalueEND'年龄'FROM test
看看,最终成了这个德行
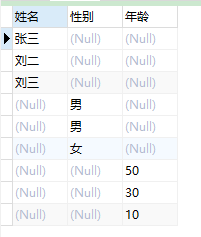
再下一步,我们就需要对全部数据进行聚合,根据前面了解到的聚合函数,我们可以选择使用max()
SELECT max(CASEtypeWHEN1THENvalueEND)'姓名', max(CASEtypeWHEN2THENvalueEND)'性别', max(CASEtypeWHEN3THENvalueEND)'年龄'FROM testGROUPBY t_id;--第二种语法SELECT max(CASEWHENtype=1THENvalueEND)'姓名', max(CASEWHENtype=2THENvalueEND)'性别', max(CASEWHENtype=3THENvalueEND)'年龄'FROM testGROUPBY t_id;
这样我们就完成了行转列,之后如果有遇到这样的需求,我们也可以使用相同的方式来实现:
主要的是要找到其中数据的规律
如果单纯的只是聚合的话,那么最终只能展示出一条数据,所以这里我们需要进行分组
GROUP BY不了解没关系,后面我们会详细聊到
if()
除了采用case之外,还有其他的方式我们来看看
SELECT max(if(type=1,value,''))'姓名', max(if(type=2,value,''))'性别', max(if(type=3,value,0))'年龄'FROM testGROUPBY t_id
if()表示如果条件满足,就返回第一个值,否则就返回第二个值
除此之外,如果我们想要给NULL值的数据查询出默认值,可以通过ifnull()来操作
--如果`account`为`null`,那么显示为0selectifnull(account,0)fromtb_user;
分页排序
常规分页
现在上面的查询都是匹配出符合条件的全部数据,如果在实际开发中数量很大的情况下这种方式很可能会将服务器拖垮,所以这里我们要将数据一页一页的显示出来
在MySQL中,通过limit关键字来进行分页
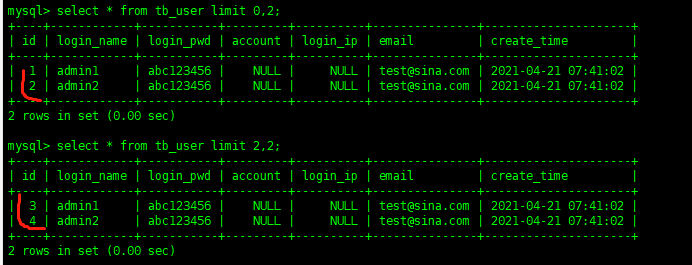
select*fromtb_userlimit0,2
前一个参数表示开始位置,后一个参数表示显示条数
分页优化
有这么一个场景:MySQL中有2000W的数据,现在要分页显示第1000W之后的10条数据,那么通过常规的方式是这样的:
select*fromtb_userlimit10000000,10
这里我们来说一说limit是如何进行分页的
limit在分页的时候会查询到需要显示的开始位置,然后丢弃掉查询出的数据,从那个位置开始,继续向后读取显示条数的数据所以说如果开始位置越大,那么需要读取的数据就越多,查询时间也就越长
这里给出一个优化方案:给定数据的查询范围,最好是索引列(索引列可以加快查询效率)
select*fromtb_userwhereid>10000000limit10;select*fromtb_userwhereid>10000000limit010;
limit后如果只跟一个参数,那么这个参数只表示显示条数
关联查询
目前我们的查询都是单表查询,我们在工作中的查询SQL基本上都涉及到多表间的操作,这样我们就需要进行多表关联查询
下面我们再简单创建一张表,然后再看看如果进行多表关联查询
createtabletb_order( idbigintprimarykeyauto_increment,user_idbigintcomment'所属用户',order_titlevarchar(50)comment'订单名称')comment'订单表';insertintotb_order(user_id,order_title)values(1,'订单-1'),(1,'订单-2'),(1,'订单-3'),(2,'订单-4'),(5,'订单-5'),(7,'订单-71');
等值查询
想要进行关联查询的话,SQL是这么操作的
select*fromtb_user,tb_orderwheretb_user.id=tb_order.user_id;
等值查询也就是说:两个表中包含相同的列名,在查询的时候匹配相同列名
对比等值查询,还存在非等值查询:两个表中没有相同的列名,但是某一个列在另一张表的列的范围之中
范围查询我们已经介绍过了,通过 **between … and …**来查询
子查询
所谓的子查询我们可以理解为:
嵌套在其他SQL语句中的完整SQL语句
还是上面的查询,我们换一种方式
select*fromtb_orderwhereuser_id=(selectidfromtb_userwhereid=1);select*fromtb_orderwhereuser_idin(selectidfromtb_user);
根据子查询返回结果的不同,子查询也可以分为不同类型
SQL1只返回了一条数据,而且在查询的时候通过等值来判断的,就可以称为单行子查询
SQL2很明显,就是多行子查询
子查询除了用在where条件之后,也可以用在显示列中
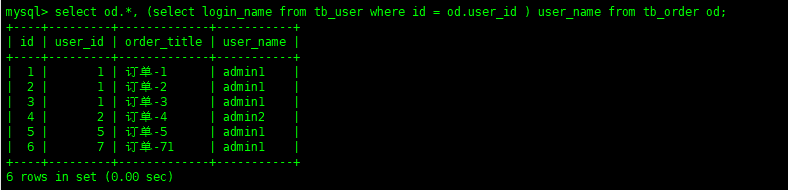
selectod.*,(selectlogin_namefromtb_userwhereid=od.user_id)fromtb_orderod;
左关联
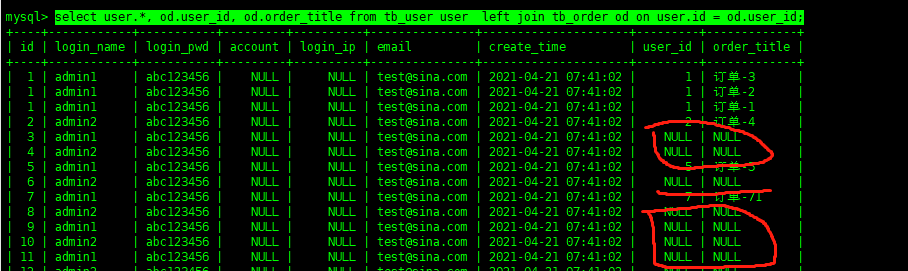
左关联查询已left join为主要关键点,两表中的关键字段通过on来进行关联,通过这种方式查询出的数据已左侧表为主,如果其关联的表中不存在数据,那么就返回NULL
select user.*,od.user_id,od.order_titlefromtb_useruserleftjointb_orderodonuser.id=od.user_id;
右关联
右关联已right join为主要关键点,数据已右侧的关联表为主,其他的操作方式和左关联一样
select user.*,od.user_id,od.order_titlefromtb_useruserrightjointb_orderodonuser.id=od.user_id;
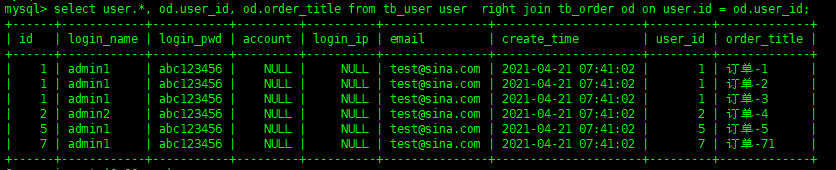
而且可以看出来,在数据的展示上,右侧表没有在左侧表有对应数据的话,那么左侧表的数据是不会显示出来的
如果在实际工作中的查询都是这么简单的话,简直不要太舒服
聚合查询
前面聊到了聚合函数,聚合函数对一组数据执行计算,并返回单条值。
很多情况下,如果我们想通过聚合函数对表中数据进行分组操作的话,那么就需要采用group by来进行查询
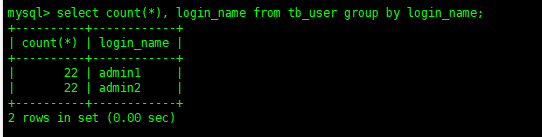
就目前表中的数据,我们可以做一个场景:
计算出表中每个登录账号有多少条记录
selectcount(*),login_namefromtb_usergroupbylogin_name
其实每个查询语法的使用都非常简单
如果想要对聚合查询出来的数据进行条件筛选,不能使用where来查询,需要通过having来筛选
selectcount(*),login_namefromtb_usergroupbylogin_namehavinglogin_name='admin1';

还需要注意的是:
当前列没有通过
group by分组,那么无法通过having来查询
语法问题

如果我们在操作的时候遇到了这样的问题:这是由于显示列中包含没有分组的列,由sql_mode的模式来决定的。先来查看下默认设置
主要的是语法不规范
--ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTIONselect@@sql_mode;

setsql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
根据提示修改就好
关于“MySQL表数据操作实例分析”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
MySQL表数据操作实例分析的详细内容,希望对您有所帮助,信息来源于网络。