怎么在Python中使用Scrapy爬取豆瓣图片
导读:本文共3528.5字符,通常情况下阅读需要12分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目创建的项目结构如下2.为了方便使用pycharm执行scrapy项目,新建main.pyfromscrapyimportcmdlinecmdline.execute("scrapycrawlbanciyuan"... ...
音频解说
目录
(为您整理了一些要点),点击可以直达。1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目
创建的项目结构如下
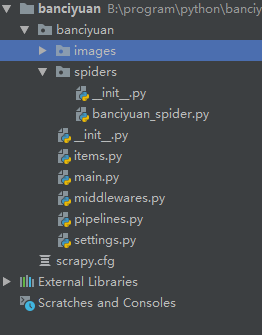
2.为了方便使用pycharm执行scrapy项目,新建main.py
fromscrapyimportcmdlinecmdline.execute("scrapycrawlbanciyuan".split())再edit configuration
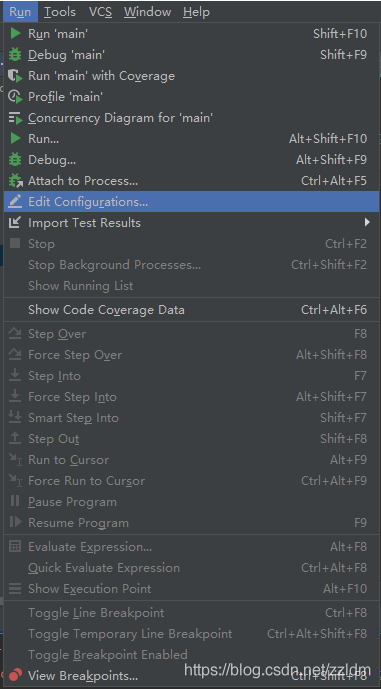
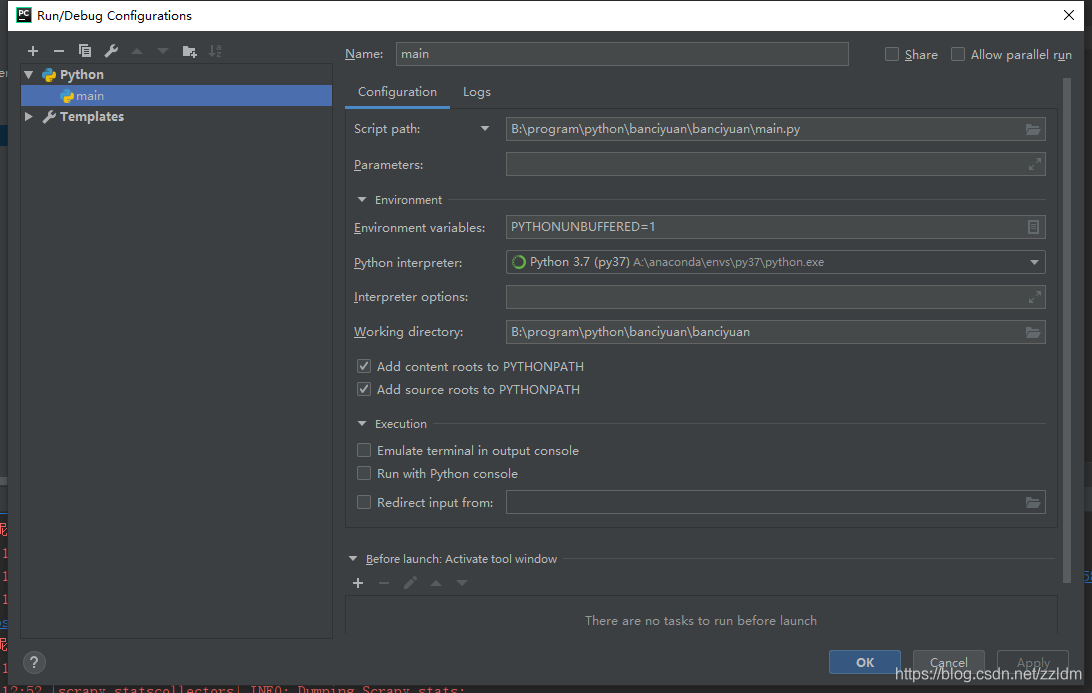
然后进行如下设置,设置后之后就能通过运行main.py运行scrapy项目了
3.分析该HTML页面,创建对应spider
fromscrapyimportSpiderimportscrapyfrombanciyuan.itemsimportBanciyuanItemclassBanciyuanSpider(Spider):name='banciyuan'allowed_domains=['movie.douban.com']start_urls=["https://movie.douban.com/celebrity/1025156/photos/"]url="https://movie.douban.com/celebrity/1025156/photos/"defparse(self,response):num=response.xpath('//div[@class="paginator"]/a[last()]/text()').extract_first('')print(num)foriinrange(int(num)):suffix='?type=C&start='+str(i*30)+'&sortby=like&size=a&subtype=a'yieldscrapy.Request(url=self.url+suffix,callback=self.get_page)defget_page(self,response):href_list=response.xpath('//div[@class="article"]//div[@class="cover"]/a/@href').extract()#print(href_list)forhrefinhref_list:yieldscrapy.Request(url=href,callback=self.get_info)defget_info(self,response):src=response.xpath('//div[@class="article"]//div[@class="photo-show"]//div[@class="photo-wp"]/a[1]/img/@src').extract_first('')title=response.xpath('//div[@id="content"]/h2/text()').extract_first('')#print(response.body)item=BanciyuanItem()item['title']=titleitem['src']=[src]yielditem4.items.py
#Defineherethemodelsforyourscrapeditems##Seedocumentationin:#https://docs.scrapy.org/en/latest/topics/items.htmlimportscrapyclassBanciyuanItem(scrapy.Item):#definethefieldsforyouritemherelike:src=scrapy.Field()title=scrapy.Field()
pipelines.py
#Defineyouritempipelineshere##Don'tforgettoaddyourpipelinetotheITEM_PIPELINESsetting#See:https://docs.scrapy.org/en/latest/topics/item-pipeline.html#usefulforhandlingdifferentitemtypeswithasingleinterfacefromitemadapterimportItemAdapterfromscrapy.pipelines.imagesimportImagesPipelineimportscrapyclassBanciyuanPipeline(ImagesPipeline):defget_media_requests(self,item,info):yieldscrapy.Request(url=item['src'][0],meta={'item':item})deffile_path(self,request,response=None,info=None,*,item=None):item=request.meta['item']image_name=item['src'][0].split('/')[-1]#image_name.replace('.webp','.jpg')path='%s/%s'%(item['title'].split('')[0],image_name)returnpathsettings.py
#Scrapysettingsforbanciyuanproject##Forsimplicity,thisfilecontainsonlysettingsconsideredimportantor#commonlyused.Youcanfindmoresettingsconsultingthedocumentation:##https://docs.scrapy.org/en/latest/topics/settings.html#https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#https://docs.scrapy.org/en/latest/topics/spider-middleware.htmlBOT_NAME='banciyuan'SPIDER_MODULES=['banciyuan.spiders']NEWSPIDER_MODULE='banciyuan.spiders'#Crawlresponsiblybyidentifyingyourself(andyourwebsite)ontheuser-agentUSER_AGENT={'User-Agent':'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/71.0.3578.80Safari/537.36'}#Obeyrobots.txtrulesROBOTSTXT_OBEY=False#ConfiguremaximumconcurrentrequestsperformedbyScrapy(default:16)#CONCURRENT_REQUESTS=32#Configureadelayforrequestsforthesamewebsite(default:0)#Seehttps://docs.scrapy.org/en/latest/topics/settings.html#download-delay#Seealsoautothrottlesettingsanddocs#DOWNLOAD_DELAY=3#Thedownloaddelaysettingwillhonoronlyoneof:#CONCURRENT_REQUESTS_PER_DOMAIN=16#CONCURRENT_REQUESTS_PER_IP=16#Disablecookies(enabledbydefault)#COOKIES_ENABLED=False#DisableTelnetConsole(enabledbydefault)#TELNETCONSOLE_ENABLED=False#Overridethedefaultrequestheaders:#DEFAULT_REQUEST_HEADERS={#'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',#'Accept-Language':'en',#}#Enableordisablespidermiddlewares#Seehttps://docs.scrapy.org/en/latest/topics/spider-middleware.html#SPIDER_MIDDLEWARES={#'banciyuan.middlewares.BanciyuanSpiderMiddleware':543,#}#Enableordisabledownloadermiddlewares#Seehttps://docs.scrapy.org/en/latest/topics/downloader-middleware.html#DOWNLOADER_MIDDLEWARES={#'banciyuan.middlewares.BanciyuanDownloaderMiddleware':543,#}#Enableordisableextensions#Seehttps://docs.scrapy.org/en/latest/topics/extensions.html#EXTENSIONS={#'scrapy.extensions.telnet.TelnetConsole':None,#}#Configureitempipelines#Seehttps://docs.scrapy.org/en/latest/topics/item-pipeline.htmlITEM_PIPELINES={'banciyuan.pipelines.BanciyuanPipeline':1,}IMAGES_STORE='./images'#EnableandconfiguretheAutoThrottleextension(disabledbydefault)#Seehttps://docs.scrapy.org/en/latest/topics/autothrottle.html#AUTOTHROTTLE_ENABLED=True#Theinitialdownloaddelay#AUTOTHROTTLE_START_DELAY=5#Themaximumdownloaddelaytobesetincaseofhighlatencies#AUTOTHROTTLE_MAX_DELAY=60#TheaveragenumberofrequestsScrapyshouldbesendinginparallelto#eachremoteserver#AUTOTHROTTLE_TARGET_CONCURRENCY=1.0#Enableshowingthrottlingstatsforeveryresponsereceived:#AUTOTHROTTLE_DEBUG=False#EnableandconfigureHTTPcaching(disabledbydefault)#Seehttps://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings#HTTPCACHE_ENABLED=True#HTTPCACHE_EXPIRATION_SECS=0#HTTPCACHE_DIR='httpcache'#HTTPCACHE_IGNORE_HTTP_CODES=[]#HTTPCACHE_STORAGE='scrapy.extensions.httpcache.FilesystemCacheStorage'5.爬取结果
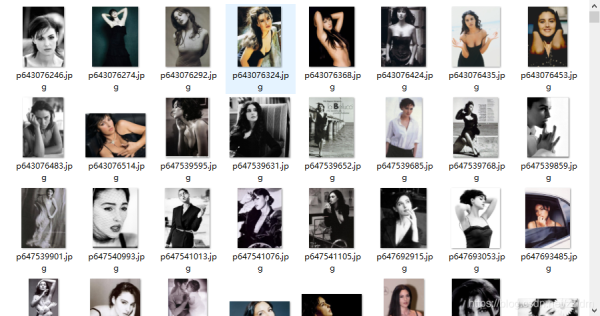
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">本文:
怎么在Python中使用Scrapy爬取豆瓣图片的详细内容,希望对您有所帮助,信息来源于网络。