Spark启动时的master参数以及Spark的部署方法
导读:本文共2661字符,通常情况下阅读需要9分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 我们在初始化SparkConf时,或者提交Spark任务时,都会有master参数需要设置,如下:conf = SparkConf().setAppName(appName).setMaster(master) sc = SparkContext(conf=conf) /bin/spark-submit \ --cluster clust... ...
目录
(为您整理了一些要点),点击可以直达。
我们在初始化SparkConf时,或者提交Spark任务时,都会有master参数需要设置,如下:
但是这个master到底是何含义呢?文档说是设定master url,但是啥是master url呢?说到这就必须先要了解下Spark的部署方式了。
我们要部署Spark这套计算框架,有多种方式,可以部署到一台计算机,也可以是多台(cluster)。我们要去计算数据,就必须要有计算机帮我们计算,当然计算机越多(集群规模越大),我们的计算力就越强。但有时候我们只想在本机做个试验或者小型的计算,因此直接部署在单机上也是可以的。Spark部署方式可以用如下图形展示:
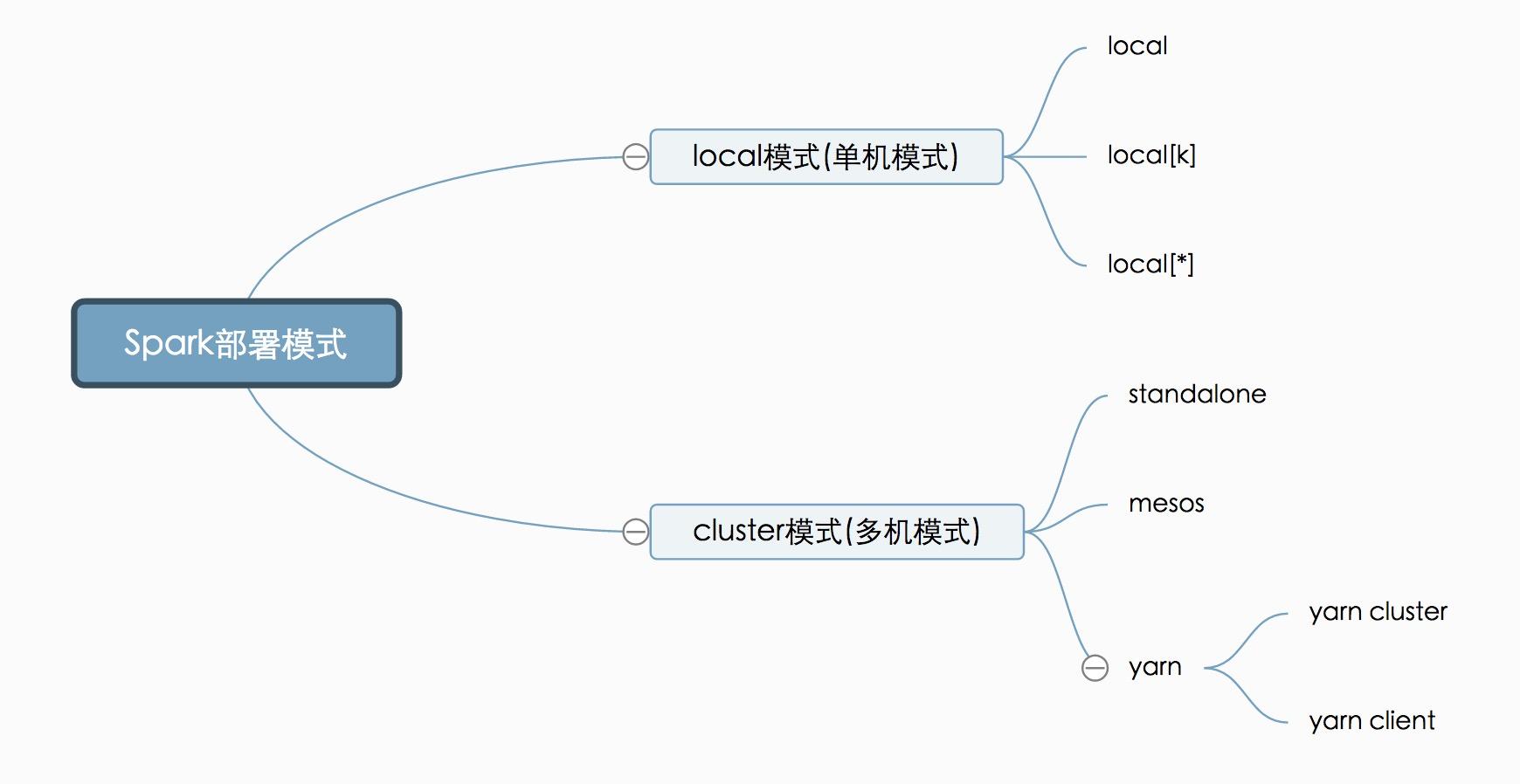
下面我们就来分别介绍下。
Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。它可以通过以下集中方式设置master。
local:所有计算都运行在一个线程当中,没有任何并行计算,通常我们在本机执行一些测试代码,或者练手,就用这种模式。
local[K]:指定使用几个线程来运行计算,比如local[4]就是运行4个worker线程。通常我们的cpu有几个core,就指定几个线程,最大化利用cpu的计算能力
local[*]:这种模式直接帮你按照cpu最多cores来设置线程数了。
使用示例:
总而言之这几种local模式都是运行在本地的单机版模式,通常用于练手和测试,而实际的大规模计算就需要下面要介绍的cluster模式。
cluster模式肯定就是运行很多机器上了,但是它又分为以下三种模式,区别在于谁去管理资源调度。(说白了,就好像后勤管家,哪里需要资源,后勤管家要负责调度这些资源)
这种模式下,Spark会自己负责资源的管理调度。它将cluster中的机器分为master机器和worker机器,master通常就一个,可以简单的理解为那个后勤管家,worker就是负责干计算任务活的苦劳力。具体怎么配置可以参考Spark Standalone Mode
使用standalone模式示例:
--master就是指定master那台机器的地址和端口,我想这也正是--master参数名称的由来吧。
这里就很好理解了,如果使用mesos来管理资源调度,自然就应该用mesos模式了,示例如下:
同样,如果采用yarn来管理资源调度,就应该用yarn模式,由于很多时候我们需要和mapreduce使用同一个集群,所以都采用Yarn来管理资源调度,这也是生产环境大多采用yarn模式的原因。yarn模式又分为yarn cluster模式和yarn client模式:
yarn cluster:这个就是生产环境常用的模式,所有的资源调度和计算都在集群环境上运行。
yarn client:这个是说Spark Driver和ApplicationMaster进程均在本机运行,而计算任务在cluster上。
使用示例:
Spark启动时的master参数以及Spark的部署方法的详细内容,希望对您有所帮助,信息来源于网络。