关于pandas.DataFrame.drop_duplicates的用法简介
导读:本文共1181.5字符,通常情况下阅读需要4分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 如下所示:DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)subset考虑重复发生在哪一列,默认考虑所有列,就是在任何一列上出现重复都算作是重复数据keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删... ...
目录
(为您整理了一些要点),点击可以直达。如下所示:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
subset考虑重复发生在哪一列,默认考虑所有列,就是在任何一列上出现重复都算作是重复数据
keep 包含三个参数first, last, False,first是指,保留搜索到的第一个重复数据,之后的都删除;last是指,保留搜索到的最后一个重复数据,之前的搜索到的重复数据都删除,False是指,把所有搜索到的重复数据都删除,一个都不保留,即如果有两行数据重复,把两行数据都删除,而不是保留其中一行。默认参数是first。
补充知识:python3删除数据重复值,只保留第一项。drop_duplicates()函数使用介绍
原始数据如下:
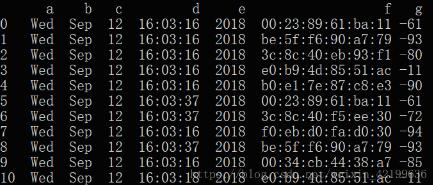
f 列的前3个数据都有重复项,现在要将重复值删去,只保留第一项或最后一项。
使用drop_duplicates()
drop_duplicates(self, subset=None, keep='first', inplace=False)
subset :如['a']代表a列中的重复值全部被删除
keep:保留第一个值,参数为first,last
inplace:是否替换原来的df,默认为False
import pandas as pddata = pd.read_table("C:/Users/xujinhua/Desktop/aa/a.txt",header=None, names=['a','b','c','d','e','f','g']) #读取文件数据,并将列命名为abcdefdata.drop_duplicates(subset='f', keep='first', inplace=True)print(data)结果:
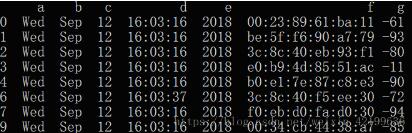
可以看到 f 列中的重复值都被删除,且保留了第一项
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">关于pandas.DataFrame.drop_duplicates的用法简介的详细内容,希望对您有所帮助,信息来源于网络。