基于CRF序列标注的中文依存句法分析器的Java实现是怎么样的
导读:本文共2113.5字符,通常情况下阅读需要7分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 这是一个基于CRF的中文依存句法分析器,内部CRF模型的特征函数采用 双数组Trie树(DoubleArrayTrie)储存,解码采用特化的维特比后向算法。相较于最大熵依存句法分析器的实现,分析速度翻了一倍,达到了1262.8655 sent/s开源项目本文代码已集成到HanLP中开源项目中,最新hanlp1.7版本已经发布CRF简介CRF是序列标注场景中常用的... ...
目录
(为您整理了一些要点),点击可以直达。这是一个基于CRF的中文依存句法分析器,内部CRF模型的特征函数采用 双数组Trie树(DoubleArrayTrie)储存,解码采用特化的维特比后向算法。相较于最大熵依存句法分析器的实现,分析速度翻了一倍,达到了1262.8655 sent/s
开源项目
本文代码已集成到HanLP中开源项目中,最新hanlp1.7版本已经发布
CRF简介
CRF是序列标注场景中常用的模型,比HMM能利用更多的特征,比MEMM更能抵抗标记偏置的问题。在生产中经常使用的训练工具是CRF++,关于CRF++的使用以及模型格式请参阅《CRF++模型格式说明》。
CRF训练
语料库
与《最大熵依存句法分析器的实现》相同,采用清华大学语义依存网络语料的20000句作为训练集。
预处理
依存关系事实上由三个特征构成——起点、终点、关系名称。在本CRF模型中暂时忽略掉关系名称(在下文可以利用其它模型补全)。
根据依存文法理论, 我们可以知道决定两个词之间的依存关系主要有二个因素: 方向和距离。因此我们将类别标签定义为具有如下的形式:
[ + |- ] dPOS
其中, [ + | – ]表示方向, + 表示支配词在句中的位置出现在从属词的后面, – 表示支配词出现在从属词的前面; POS表示支配词具有的词性类别; d表示距离。
比如原树库:
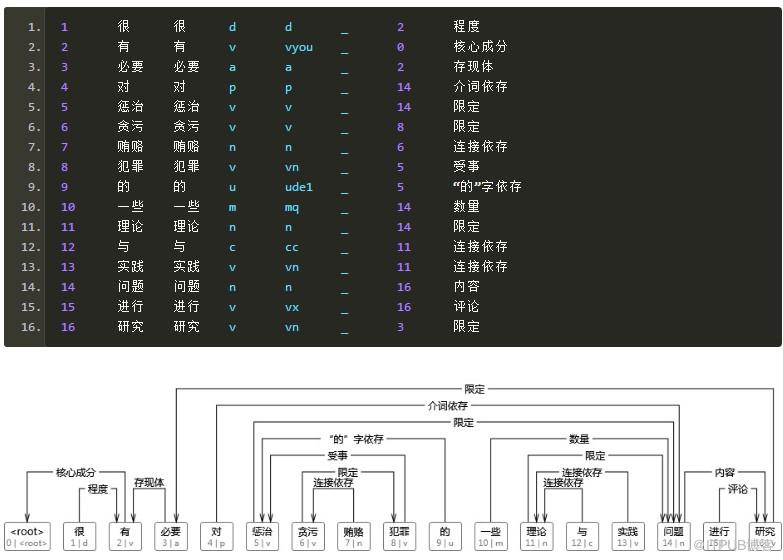
转换后:
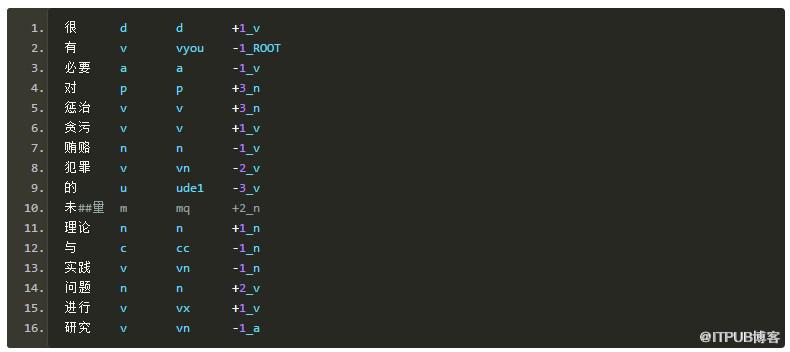
特征模板
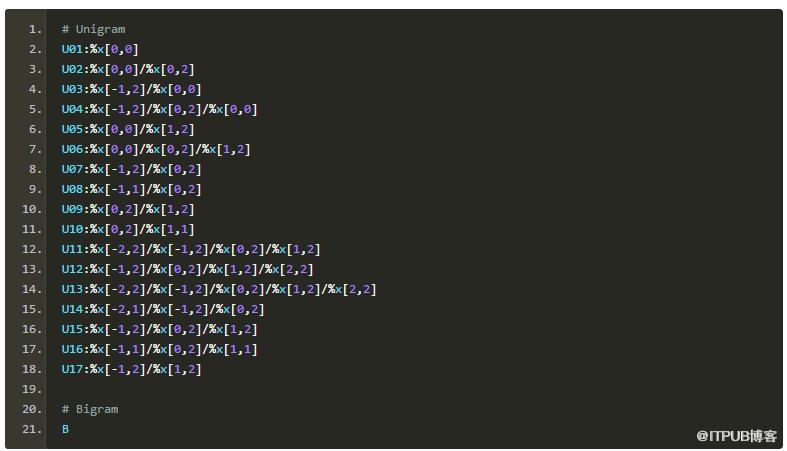
训练参数
1.crf_learn-f3-c4.0-p3template.txttrain.txtmodel-t
我的试验条件(机器性能)有限,每迭代一次要花5分钟,最后只能设定最大迭代次数为100。经过痛苦的迭代,得到了一个效果非常有限的模型,其serr高达50%,暂时只做算法测试用。
解码
标准的维特比算法假定所有标签都是合法的,但是在本CRF模型中,标签还受到句子的约束。比如最后一个词的标签不可能是+nPos,必须是负数,而且任何词的[+/-]nPos都得保证后面(或前面,当符号为负的时候)有n个词语的标签是Pos。所以我覆写了CRF的维特比tag算法,代码如下:
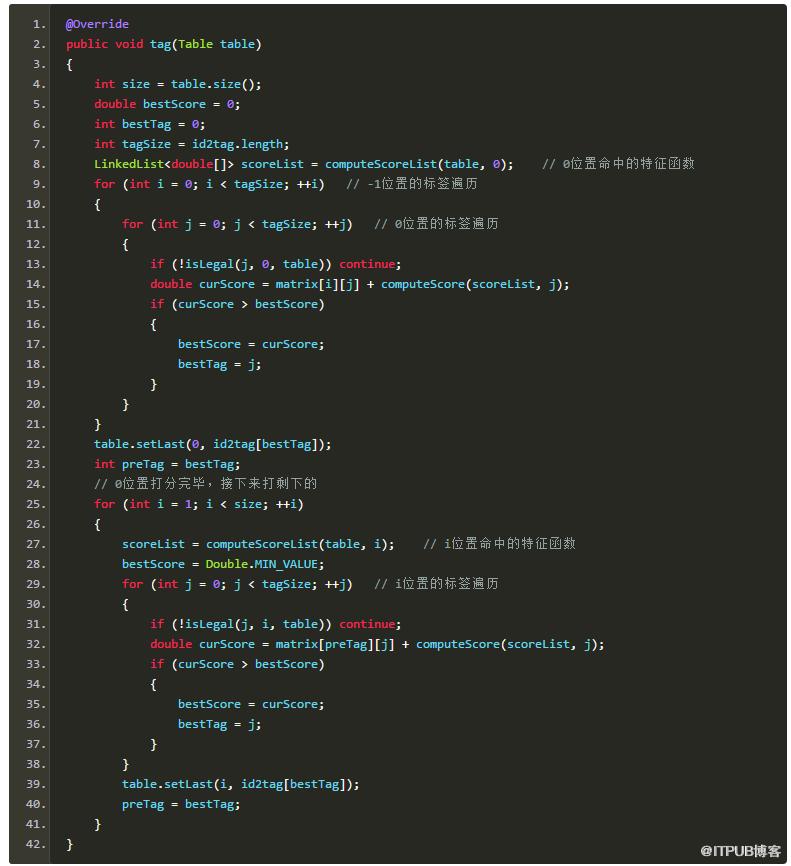
注意上面的
1.if (!isLegal(j, i, table)) continue;
保证了标签的合法性。
这一步的结果:

后续处理
有了依存的对象,还需要知道这条依存关系到底是哪种具体的名称。我从树库中统计了两个词的词与词性两两组合出现概率,姑且称其为2gram模型,用此模型接受依存边两端的词语,输出其最可能的关系名称。
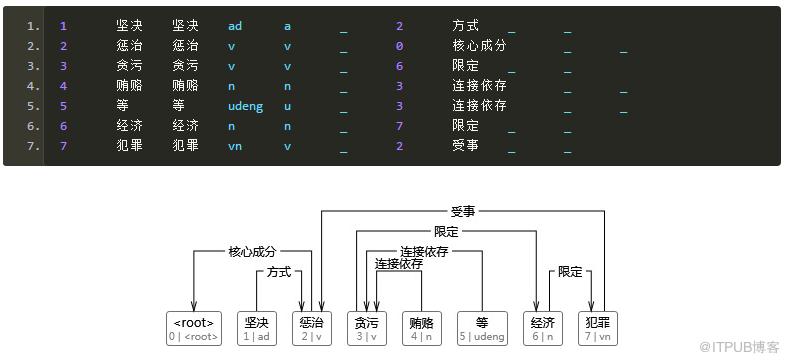
最终结果
转换为CoNLL格式输出:
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">基于CRF序列标注的中文依存句法分析器的Java实现是怎么样的的详细内容,希望对您有所帮助,信息来源于网络。