如何用Numpy分析各类用户占比
导读:本文共1525.5字符,通常情况下阅读需要5分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 分析目标观察上次的数据,数据中有的数据有会员与非会员两种用户类别。这次我们主要分析一下两种类别用户在数据中占比。数据读取与数据清洗根据流程示意图我们主要遵循下面几个步骤:此处代码为:#数据读取,数据清洗defread_clean_data():clndata_arr_list=[]fordata_filenameindata_filenames:file=os.... ...
音频解说
目录
(为您整理了一些要点),点击可以直达。分析目标
观察上次的数据,数据中有的数据有会员与非会员两种用户类别。
这次我们主要分析一下两种类别用户在数据中占比。
数据读取与数据清洗
根据流程示意图我们主要遵循下面几个步骤:

此处代码为:
#数据读取,数据清洗
defread_clean_data():
clndata_arr_list=[]
fordata_filenameindata_filenames:
file=os.path.join(data_path,data_filename)
data_arr=np.loadtxt(file,skiprows=1,delimiter=',',dtype=bytes).astype(str)
cln_arr=np.core.defchararray.replace(data_arr[:,-1],'"','')
cln_arr=cln_arr.reshape(-1,1)
clndata_arr_list.append(cln_arr)
year_cln_arr=np.concatenate(clndata_arr_list)
returnyear_cln_arr
这里需要注意两点:
因为数据较大,我们没有数据文件具体数据量,所以在使用
numpy.reshape时我们可以使用numpy.reshape(-1,1)这样numpy可以使用统计后的具体数值替换-1。我们对数据的需求不再是获取时间的平均值,只需获取数据最后一列并使用
concatenate方法堆叠到一起以便下一步处理。
数据分析
根据这次的分析目标,我们取出最后一列Member type。
在上一步我们已经获取了全部的数值,在本部只需筛选统计出会员与非会员的数值就可以了。
我们可以先看下完成后的这部分代码:
#数据分析
defmean_data(year_cln_arr):
member=year_cln_arr[year_cln_arr=='Member'].shape[0]
casual=year_cln_arr[year_cln_arr=='Casual'].shape[0]
users=[member,casual]
print(users)
returnusers
同样,这里使用numpy.shape获取用户分类的具体数据。
结果展示
生成的饼图:
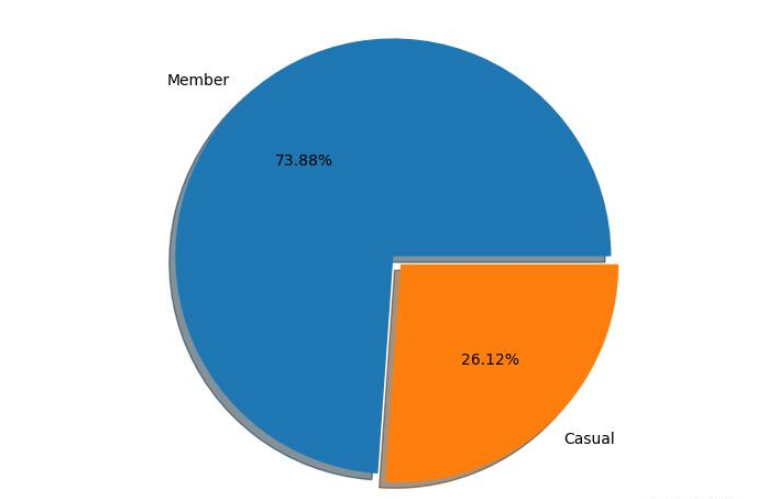
下面是生成饼图的代码:
#结果展示
plt.figure()
plt.pie(users,labels=['Member','Casual'],autopct='%.2f%%',shadow=True,explode=(0.05,0))
plt.axis('equal')
plt.tight_layout()
plt.savefig(os.path.join(output_path,'./piechart.png'))
plt.show()
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">本文:
如何用Numpy分析各类用户占比的详细内容,希望对您有所帮助,信息来源于网络。