在Python中如何通过机器学习实现人体姿势估计
导读:本文共4365.5字符,通常情况下阅读需要15分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 什么是姿态估计?姿态估计是一种跟踪人或物体运动的计算机视觉技术。这通常通过查找给定对象的关键点位置来执行。基于这些关键点,我们可以比较各种动作和姿势并得出见解。姿态估计在增强现实、动画、游戏和机器人领域得到了积极的应用。目前有几种模型可以执行姿态估计。下面给出了一些姿势估计的方法:1.Open pose2.Pose net3.Blaze pose4.Deep P... ...
目录
(为您整理了一些要点),点击可以直达。什么是姿态估计?
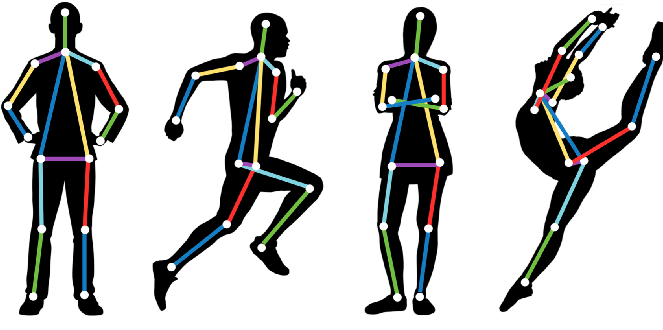
姿态估计是一种跟踪人或物体运动的计算机视觉技术。这通常通过查找给定对象的关键点位置来执行。基于这些关键点,我们可以比较各种动作和姿势并得出见解。姿态估计在增强现实、动画、游戏和机器人领域得到了积极的应用。
目前有几种模型可以执行姿态估计。下面给出了一些姿势估计的方法:
1.Open pose
2.Pose net
3.Blaze pose
4.Deep Pose
5.Dense pose
6.Deep cut
选择任何一种模型而不是另一种可能完全取决于应用程序。此外,运行时间、模型大小和易于实现等因素也可能是选择特定模型的各种原因。因此,最好从一开始就了解你的要求并相应地选择模型。
在本文中,我们将使用 Blaze pose检测人体姿势并提取关键点。该模型可以通过一个非常有用的库轻松实现,即众所周知的Media Pipe。
Media Pipe——Media Pipe是一个开源的跨平台框架,用于构建多模型机器学习管道。它可用于实现人脸检测、多手跟踪、头发分割、对象检测和跟踪等前沿模型。
Blaze Pose Detector ——大部分姿态检测依赖于由 17 个关键点组成的 COCO 拓扑结构,而Blaze姿态检测器预测 33 个人体关键点,包括躯干、手臂、腿部和面部。包含更多关键点对于特定领域姿势估计模型的成功应用是必要的,例如手、脸和脚。每个关键点都使用三个自由度以及可见性分数进行预测。Blaze Pose是亚毫秒模型,可用于实时应用,其精度优于大多数现有模型。该模型有两个版本:Blazepose lite 和 Blazepose full,以提供速度和准确性之间的平衡。
Blaze 姿势提供多种应用程序,包括健身和瑜伽追踪器。这些应用程序可以通过使用一个额外的分类器来实现,比如我们将在本文中构建的分类器。
你可以在此处了解有关Blaze Pose Detector的更多信息: https://ai.googleblog.com/2020/08/on-device-real-time-body-pose-tracking.html
2D 与 3D 姿态估计
姿势估计可以在 2D 或 3D 中完成。2D 姿态估计通过像素值预测图像中的关键点。而3D姿态估计是指预测关键点的三维空间排列作为其输出。
为姿态估计准备数据集
我们在上一节中了解到,人体姿势的关键点可以用来比较不同的姿势。在本节中,我们将使用Media Pipe库本身来准备数据集。我们将拍摄两个瑜伽姿势的图像,从中提取关键点并将它们存储在一个 CSV 文件中。
你可以通过此链接从 Kaggle 下载数据集
该数据集包含 5 个瑜伽姿势,但是,在本文中,我只采用了两个姿势。如果需要,你可以使用所有这些,程序将保持不变。
importmediapipeasmpimportcv2importtimeimportnumpyasnpimportpandasaspdimportosmpPose=mp.solutions.posepose=mpPose.Pose()mpDraw=mp.solutions.drawing_utils#Fordrawingkeypointspoints=mpPose.PoseLandmark#Landmarkspath="DATASET/TRAIN/plank"#enterdatasetpathdata=[]forpinpoints:x=str(p)[13:]data.append(x+"_x")data.append(x+"_y")data.append(x+"_z")data.append(x+"_vis")data=pd.DataFrame(columns=data)#Emptydataset
在上面的代码片段中,我们首先导入了有助于创建数据集的必要库。然后在接下来的四行中,我们将导入提取关键点所需的模块及其绘制工具。
接下来,我们创建一个空的 Pandas 数据框并输入列。这里的列包括由Blaze姿态检测器检测到的 33 个关键点。每个关键点包含四个属性,即关键点的 x 和 y 坐标(从 0 到 1 归一化),z 坐标表示以臀部为原点且与 x 的比例相同的地标深度,最后是可见度分数。可见性分数表示地标在图像中可见或不可见的概率。
count=0forimginos.listdir(path):temp=[]img=cv2.imread(path+"/"+img)imageWidth,imageHeight=img.shape[:2]imgRGB=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)blackie=np.zeros(img.shape)#Blankimageresults=pose.process(imgRGB)ifresults.pose_landmarks:#mpDraw.draw_landmarks(img,results.pose_landmarks,mpPose.POSE_CONNECTIONS)#drawlandmarksonimagempDraw.draw_landmarks(blackie,results.pose_landmarks,mpPose.POSE_CONNECTIONS)#drawlandmarksonblackielandmarks=results.pose_landmarks.landmarkfori,jinzip(points,landmarks):temp=temp+[j.x,j.y,j.z,j.visibility]data.loc[count]=tempcount+=1cv2.imshow("Image",img)cv2.imshow("blackie",blackie)cv2.waitKey(100)data.to_csv("dataset3.csv")#savethedataasacsvfile在上面的代码中,我们单独遍历姿势图像,使用Blaze姿势模型提取关键点并将它们存储在临时数组“temp”中。
迭代完成后,我们将这个临时数组作为新记录添加到我们的数据集中。你还可以使用Media Pipe本身中的绘图实用程序来查看这些地标。
在上面的代码中,我在图像以及空白图像“blackie”上绘制了这些地标,以仅关注Blaze姿势模型的结果。空白图像“blackie”的形状与给定图像的形状相同。
应该注意的一件事是,Blaze姿态模型采用 RGB 图像而不是 BGR(由 OpenCV 读取)。
获得所有图像的关键点后,我们必须添加一个目标值,作为机器学习模型的标签。你可以将第一个姿势的目标值设为 0,将另一个设为 1。之后,我们可以将这些数据保存到 CSV 文件中,我们将在后续步骤中使用该文件创建机器学习模型。

你可以从上图中观察数据集的外观。
创建姿势估计模型
现在我们已经创建了我们的数据集,我们只需要选择一种机器学习算法来对姿势进行分类。在这一步中,我们将拍摄一张图像,运行 blaze 姿势模型(我们之前用于创建数据集)以获取该图像中人物的关键点,然后在该测试用例上运行我们的模型。
该模型有望以高置信度给出正确的结果。在本文中,我将使用 sklearn 库中的 SVC(支持向量分类器)来执行分类任务。
fromsklearn.svmimportSVCdata=pd.read_csv("dataset3.csv")X,Y=data.iloc[:,:132],data['target']model=SVC(kernel='poly')model.fit(X,Y)mpPose=mp.solutions.posepose=mpPose.Pose()mpDraw=mp.solutions.drawing_utilspath="enterimagepath"img=cv2.imread(path)img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)results=pose.process(imgRGB)ifresults.pose_landmarks:landmarks=results.pose_landmarks.landmarkforjinlandmarks:temp=temp+[j.x,j.y,j.z,j.visibility]y=model.predict([temp])ify==0:asan="plank"else:asan="goddess"print(asan)cv2.putText(img,asan,(50,50),cv2.FONT_HERSHEY_SIMPLEX,1,(255,255,0),3)cv2.imshow("image",img)在上面的代码行中,我们首先从 sklearn 库中导入了 SVC(支持向量分类器)。我们已经用目标变量作为 Y 标签训练了我们之前在 SVC 上构建的数据集。
然后我们读取输入图像并提取关键点,就像我们在创建数据集时所做的那样。
最后,我们输入临时变量并使用模型进行预测。现在可以使用简单的 if-else 条件检测姿势。
模型结果
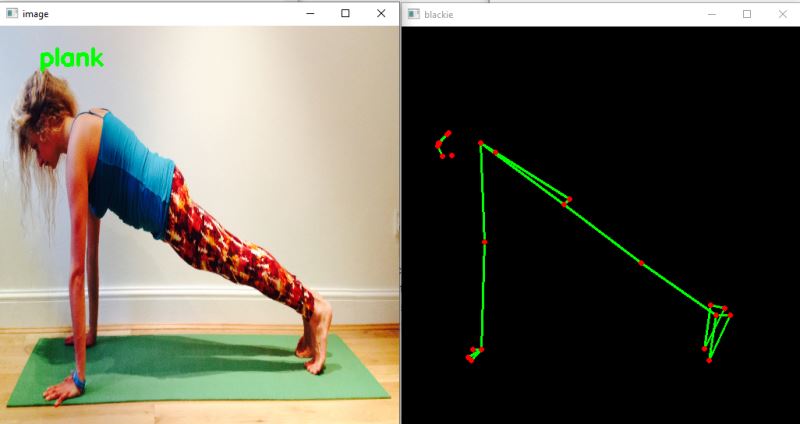
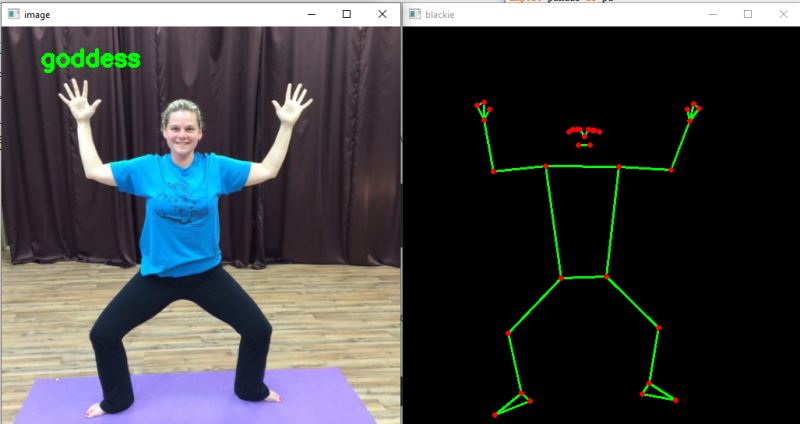
从上面的图像中,你可以观察到模型已经正确地对姿势进行了分类。你还可以在右侧看到Blaze姿势模型检测到的姿势。
在第一张图片中,如果你仔细观察,一些关键点是不可见的,但姿势分类是正确的。由于Blaze姿态模型给出的关键点属性的可见性,这是可能的。
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">在Python中如何通过机器学习实现人体姿势估计的详细内容,希望对您有所帮助,信息来源于网络。