SpringCloud服务的平滑上下线怎么实现
导读:本文共3305字符,通常情况下阅读需要11分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 整体来说,SpringCloud功能齐全,经过一段时间的踩坑后使用起来还是非常舒服的。我们的微服务,大体集成了以下内容。嗯,一个庞大的生态问题那么问题来了,SpringCloud到注册中心的注册是通过 Rest 接口调用的。它不能像 ZooKeeper那样,有问题节点反馈及时生效。也不能像 Redis 那么快的去轮训,太娇贵怕轮坏了。如下图:有三个要求:1)Se... ...
目录
(为您整理了一些要点),点击可以直达。整体来说,SpringCloud功能齐全,经过一段时间的踩坑后使用起来还是非常舒服的。
我们的微服务,大体集成了以下内容。
嗯,一个庞大的生态
问题
那么问题来了,SpringCloud到注册中心的注册是通过 Rest 接口调用的。它不能像 ZooKeeper那样,有问题节点反馈及时生效。也不能像 Redis 那么快的去轮训,太娇贵怕轮坏了。如下图:
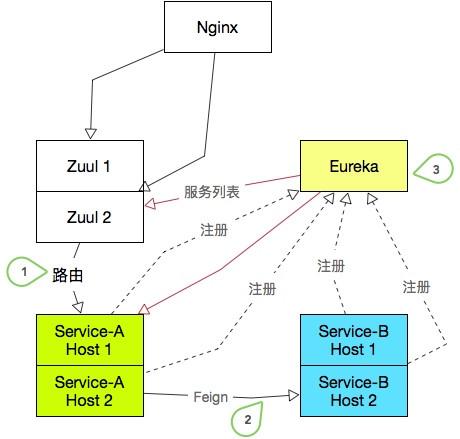
有三个要求:
1)ServiceA下线一台实例后,Zuul网关的调用不能失败
2)ServiceB下线一台实例后,ServiceA的Feign调用不能失败
3)服务上线下线,Eureka服务能够快速感知
说白了就一件事,怎样尽量缩短服务下线后Zuul和其他被依赖服务的发现时间,并在这段时间内保证请求不失败。
解决时间问题
影响因子
1) Eureka的两层缓存问题 (这是什么鬼
EurekaServer默认有两个缓存,一个是ReadWriteMap,另一个是ReadOnlyMap。有服务提供者注册服务或者维持心跳时时,会修改ReadWriteMap。当有服务调用者查询服务实例列表时,默认会从ReadOnlyMap读取(这个在原生Eureka可以配置,SpringCloud Eureka中不能配置,一定会启用ReadOnlyMap读取),这样可以减少ReadWriteMap读写锁的争用,增大吞吐量。EurekaServer定时把数据从ReadWriteMap更新到ReadOnlyMap中
2) 心跳时间
服务提供者注册服务后,会定时心跳。这个根据服务提供者的Eureka配置中的服务刷新时间决定。还有个配置是服务过期时间,这个配置在服务提供者配置但是在EurekaServer使用了,但是默认配置EurekaServer不会启用这个字段。需要配置好EurekaServer的扫描失效时间,才会启用EurekaServer的主动失效机制。在这个机制启用下:每个服务提供者会发送自己服务过期时间上去,EurekaServer会定时检查每个服务过期时间和上次心跳时间,如果在过期时间内没有收到过任何一次心跳,同时没有处于保护模式下,则会将这个实例从ReadWriteMap中去掉
3)调用者服务从Eureka拉列表的轮训间隔
4) Ribbon缓存
解决方式
1) 禁用Eureka的ReadOnlyMap缓存 (Eureka端)
eureka.server.use-read-only-response-cache:false
2) 启用主动失效,并且每次主动失效检测间隔为3s (Eureka端)
eureka.server.eviction-interval-timer-in-ms:3000
像 eureka.server.responseCacheUpdateInvervalMs 和 eureka.server.responseCacheAutoExpirationInSeconds 在启用了主动失效后其实没什么用了。默认的180s真够把人给急疯的。
3) 服务过期时间 (服务提供方)
eureka.instance.lease-expiration-duration-in-seconds:15
超过这个时间没有接收到心跳EurekaServer就会将这个实例剔除。EurekaServer一定要设置eureka.server.eviction-interval-timer-in-ms否则这个配置无效,这个配置一般为服务刷新时间配置的三倍。默认90s!
4) 服务刷新时间配置,每隔这个时间会主动心跳一次 (服务提供方)
eureka.instance.lease-renewal-interval-in-seconds:5
默认30s
5) 拉服务列表时间间隔 (客户端)
eureka.client.registryFetchIntervalSeconds:5
默认30s
6) ribbon刷新时间 (客户端)
ribbon.ServerListRefreshInterval:5000
ribbon竟然也有缓存,默认30s
这些超时时间相互影响,竟然三个地方都需要配置,一不小心就会出现服务不下线,服务不上线的囧境。不得不说SpringCloud的这套默认参数简直就是在搞笑。
重试
那么一台服务器下线,最长的不可用时间是多少呢?(即请求会落到下线的服务器上,请求失败)。赶的巧的话,这个基本时间就是 eureka.client.registryFetchIntervalSeconds+ribbon.ServerListRefreshInterval ,大约是 8 秒的时间。如果算上服务端主动失效的时间,这个时间会增加到 11秒 。
如果你只有两个实例,极端情况下服务上线的发现时间也需要11秒,那就是22秒的时间。
理想情况下,在这11秒之间,请求是失败的。加入你的QPS是1000,部署了四个节点,那么在11秒中失败的请求数量会是 1000 / 4 * 11 = 2750 ,这是不可接受的。所以我们要引入重试机制。
SpringCloud引入重试还是比较简单的。但不是配置一下就可以的,既然用了重试,那么就还需要控制超时。可以按照以下的步骤:
1) 引入pom (千万别忘了哦)
<dependency><groupId>org.springframework.retry</groupId><artifactId>spring-retry</artifactId></dependency>
2) 加入配置
ribbon.OkToRetryOnAllOperations:true#(是否所有操作都重试,若false则仅get请求重试)ribbon.MaxAutoRetriesNextServer:3#(重试负载均衡其他实例最大重试次数,不含首次实例)ribbon.MaxAutoRetries:1#(同一实例最大重试次数,不含首次调用)ribbon.ReadTimeout:30000ribbon.ConnectTimeout:3000ribbon.retryableStatusCodes:404,500,503#(那些状态进行重试)spring.cloud.loadbalancer.retry.enable:true#(重试开关)
发布系统
OK,机制已经解释清楚,但是实践起来还是很繁杂的,让人焦躁。比如有一个服务有两个实例,我要一台一台的去发布,在发布第二台之前,起码要等上11秒。如果手速太快,那就是灾难。所以一个配套的发布系统是必要的。
首先可以通过rest请求去请求Eureka,主动去隔离一台实例,多了这一步,可以减少至少3秒服务不可用的时间(还是比较划算的)。
然后通过打包工具打包,推包。依次上线替换。
市面上没有这样的持续集成哦你工具,那么发布系统就需要定制,这也是一部分工作量。
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">SpringCloud服务的平滑上下线怎么实现的详细内容,希望对您有所帮助,信息来源于网络。