Java中为什么处理排序数组比未排序数组快
导读:本文共2976.5字符,通常情况下阅读需要10分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 首先来看一下问题,下面是很简单的一段代码,随机生成一些数字,对其中大于 128 的元素求和,记录并打印求和所用时间。importjava.util.Arrays;importjava.util.Random;publicclassMain{publicstaticvoidmain(String[]args){//GeneratedataintarraySize=... ...
目录
(为您整理了一些要点),点击可以直达。首先来看一下问题,下面是很简单的一段代码,随机生成一些数字,对其中大于 128 的元素求和,记录并打印求和所用时间。
importjava.util.Arrays;
importjava.util.Random;
publicclassMain
{
publicstaticvoidmain(String[]args)
{
//Generatedata
intarraySize=32768;
intdata[]=newint[arraySize];
Randomrnd=newRandom(0);
for(intc=0;c<arraySize;++c)
data[c]=rnd.nextInt()%256;
//!!!Withthis,thenextlooprunsfaster
Arrays.sort(data);
//Test
longstart=System.nanoTime();
longsum=0;
for(inti=0;i<100000;++i)
{
//Primaryloop
for(intc=0;c<arraySize;++c)
{
if(data[c]>=128)
sum+=data[c];
}
}
System.out.println((System.nanoTime()-start)/1000000000.0);
System.out.println("sum="+sum);
}
}
我的运行结果:分别在对数组排序和不排序的前提下测试,在不排序时所用的时间比先排好序所用时间平均要多 10 ms。这不是巧合,而是必然的结果。
问题就出在那个if判断上面,在旧文顺序、条件、循环语句的底层解释中其实已经提到了造成这种结果的原因,只是旧文中没有拿出具体的例子来说明。
为了把这个问题搞明白,需要先对流水线有一定的了解。计算机是指令流驱动的,执行的是一个一个的指令,而执行一条指令,又要经过取指、译码、执行、访存、写回、更新六个阶段(不同的划分方式所包含的阶段不一样)。
六个阶段使用的硬件基本是不一样的,如果一条指令执行完再去执行另一条指令,那么在这段时间里会有很多硬件处于空闲状态,要使计算机的速度变快,那么就不能让硬件停下来,所以有了流水线技术。
流水线技术通过将指令重叠来实现几条指令并行处理,下图表示的是三阶段指令时序,即把一个指令分为三个阶段。在第一条指令的 B 阶段,A 阶段相关的硬件是空闲的,于是可以将第二条指令的 A 阶段提前操作。
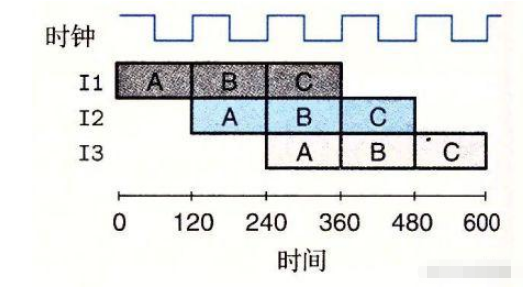
很明显,这种设计大幅提高了指令运行的效率,聪明的你可能发现问题了,要是不知道下一条指令是什么怎么办,那提前的阶段也就白干了,那样流水线不就失效了?没错,这就是导致开篇问题的原因。
让流水线出问题的情况有三种:1、数据相关,后一条指令需要用到前一条指令的运算结果;2、控制相关,比如无条件跳转,跳转的地址需要在译码阶段才能知道,所以跳转之后已经被取出的指令流水就需要清空;3、结构相关,由于一些指令需要的时钟周期长(比如浮点运算等),长时间占用硬件,导致之后的指令无法进入译码等阶段,即它们在争用同一套硬件。
代码中的if (data[c] >= 128)翻译成机器语言就是跳转指令,处理器事先并不知道要跳转到哪个分支,那难道就等知道了才开始下一条指令的取指工作吗?处理器选择了假装知道会跳转到哪个分支(不是谦虚,是真的假装知道),如果猜中了是运气好,而没有猜中那就浪费一点时间重新来干。
没有排序的数组,元素是随机排列的,每次data[c] >= 128的结果也是随机的,前面的经验就不可参考,所以下一次执行到这里理论上还是会有 50% 的可能会猜错,猜错了肯定就需要花时间来修改犯下的错误,自然就会浪费更多的时间。
对于排好序的数组,开始几次也需要靠猜,但是猜着猜着发现有规律啊,每次都是往同一个分支跳转,所以以后基本上每次都能猜中,当遍历到与 128 分界的地方,才会出现猜不中的情况,但是猜几次之后,发现这又有规律啊,每次都是朝着另外一个相同分支走的。
虽然都会猜错,但是在排好序的情况下猜错的几率远远小于未排序时的几率,最终呈现的结果就是处理排序数组比未排序数组快,其原因就是流水线发生了大量的控制相关现象,下面通俗一点,加深一下理解。
远在他方心仪多年的姑娘突然告诉你,其实她也喜欢你,激动的你三天三夜睡不着觉,决定开车前往她的城市,要和她待在一起,但是要去的路上有很多很多岔路,你只能使用的某某地图导航,作为老司机并且怀着立马要见到爱人心情的你,开车超快,什么样罚单都不在乎了。
地图定位已经跟不上你的速度了,为了尽快到达,遇到岔路你都是随机选一条路前进,遗憾的是,自己的选择不一定对(我们假设高速可以回退),走错路了就要重新回到分岔点,这就对应着未排序的情况。
现在岔路是有规律的,告诉你开始一直朝着一边走,到某个地点后会一直朝着另一边走,你只需要花点时间去探索一下开始朝左边还是右边,到了中间哪个地点会改变方向就可以了,相比之下就能节省不少时间了,尽快见到自己的爱人,这对应着排好序的情况。
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">Java中为什么处理排序数组比未排序数组快的详细内容,希望对您有所帮助,信息来源于网络。