Python深度学习神经网络基本原理的示例分析
导读:本文共1524.5字符,通常情况下阅读需要5分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 神经网络梯度下降法在详细了解梯度下降的算法之前,我们先看看相关的一些概念。 1. 步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。用上面下山的例子,步长就是在当前这一步所在位置沿着最陡峭最易下山的位置走的那一步的长度。 2.特征(feature):指的是样本中输入部分,比如2个单特征的样本(x(0)... ...
目录
(为您整理了一些要点),点击可以直达。神经网络

梯度下降法
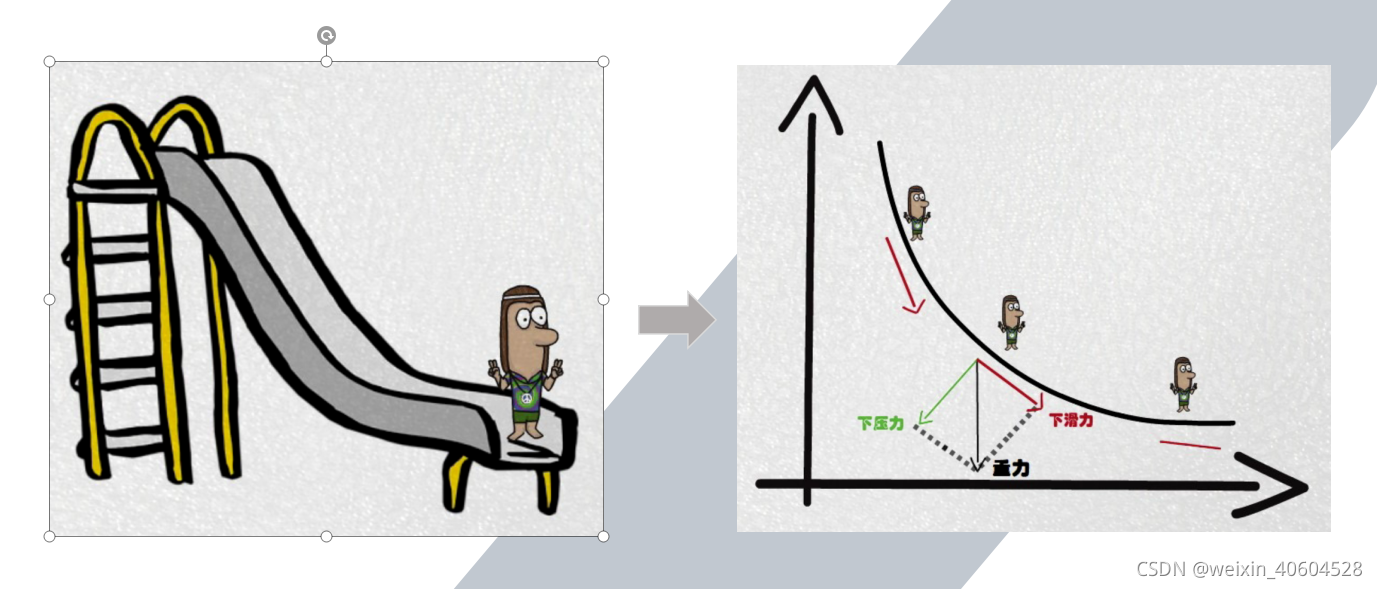
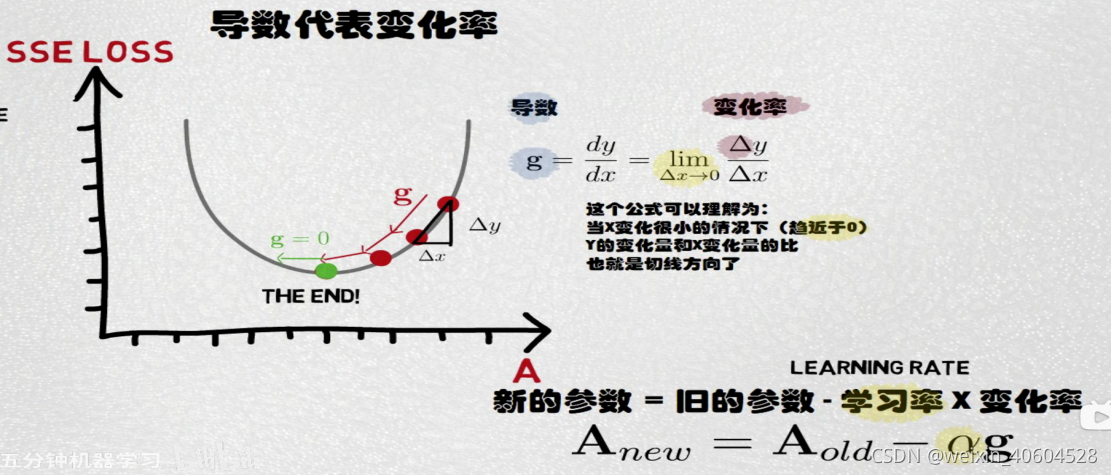
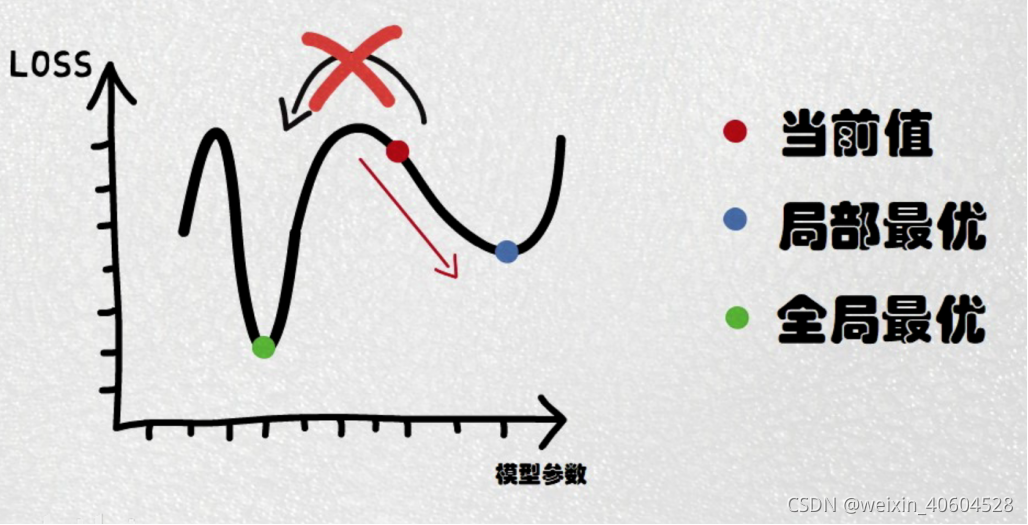
在详细了解梯度下降的算法之前,我们先看看相关的一些概念。
1. 步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。用上面下山的例子,步长就是在当前这一步所在位置沿着最陡峭最易下山的位置走的那一步的长度。
2.特征(feature):指的是样本中输入部分,比如2个单特征的样本(x(0),y(0)),(x(1),y(1))(x(0),y(0)),(x(1),y(1)),则第一个样本特征为x(0)x(0),第一个样本输出为y(0)y(0)。
3. 假设函数(hypothesis function):在监督学习中,为了拟合输入样本,而使用的假设函数,记为hθ(x)hθ(x)。比如对于单个特征的m个样本(x(i),y(i))(i=1,2,...m)(x(i),y(i))(i=1,2,...m),可以采用拟合函数如下: hθ(x)=θ0+θ1xhθ(x)=θ0+θ1x。
4. 损失函数(loss function):为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。损失函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。在线性回归中,损失函数通常为样本输出和假设函数的差取平方。比如对于m个样本(xi,yi)(i=1,2,...m)(xi,yi)(i=1,2,...m),采用线性回归,损失函数为:
J(θ0,θ1)=∑i=1m(hθ(xi)−yi)2J(θ0,θ1)=∑i=1m(hθ(xi)−yi)2
其中xixi表示第i个样本特征,yiyi表示第i个样本对应的输出,hθ(xi)hθ(xi)为假设函数。
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">Python深度学习神经网络基本原理的示例分析的详细内容,希望对您有所帮助,信息来源于网络。