基于node.js怎么制作简单爬虫
导读:本文共3229.5字符,通常情况下阅读需要11分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 目标:爬取 http://tweixin.yueyishujia.com/webapp/build/html/ 网站的所有门店发型师的基本信息。思路:访问上述网站,通过chrome浏览器的network对网页内容分析,找到获取各个门店发型师的接口,对参数及返回数据进行分析,遍历所有门店的所有发型师,直到遍历完毕,同事将信息存储到本地。步骤一:安装node.js下... ...
目录
(为您整理了一些要点),点击可以直达。目标:爬取 http://tweixin.yueyishujia.com/webapp/build/html/ 网站的所有门店发型师的基本信息。
思路:访问上述网站,通过chrome浏览器的network对网页内容分析,找到获取各个门店发型师的接口,对参数及返回数据进行分析,遍历所有门店的所有发型师,直到遍历完毕,同事将信息存储到本地。
步骤一:安装node.js
下载并安装node,此步骤比较简单就不详细解释了,有问题的可以直接问一下度娘。
步骤二:建立工程
1)打开dos命令条,cd进入想要创建项目的路径(我将此项目直接放在了E盘,以下皆以此路径为例);
2)mkdir node (创建一个文件夹用来存放项目,我这里取名为node);
3)cd 进入名为node的文件夹,并执行npm init初始化工程(期间会让填写一些信息,我是直接回车的);
步骤三:创建爬取到的数据存放的文件夹
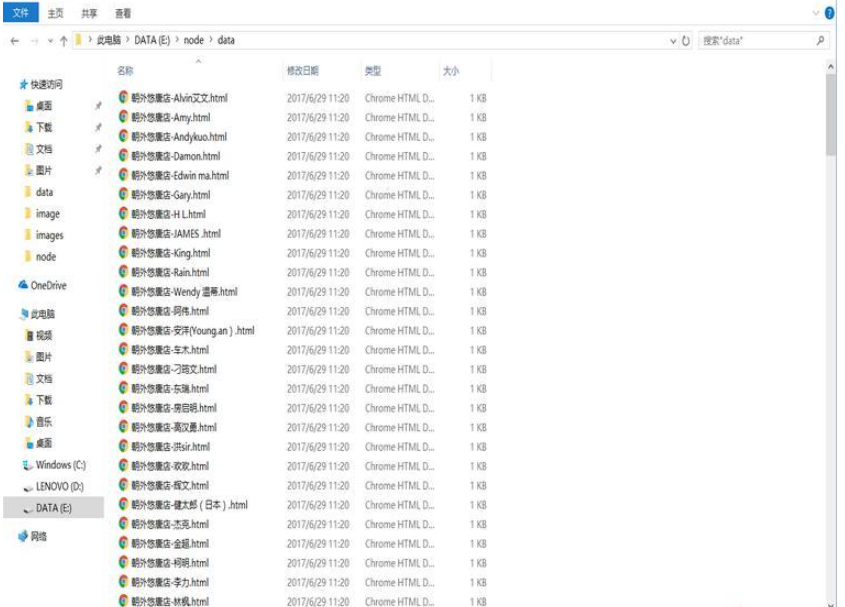
1)创建data文件夹用来存放发型师基本信息;
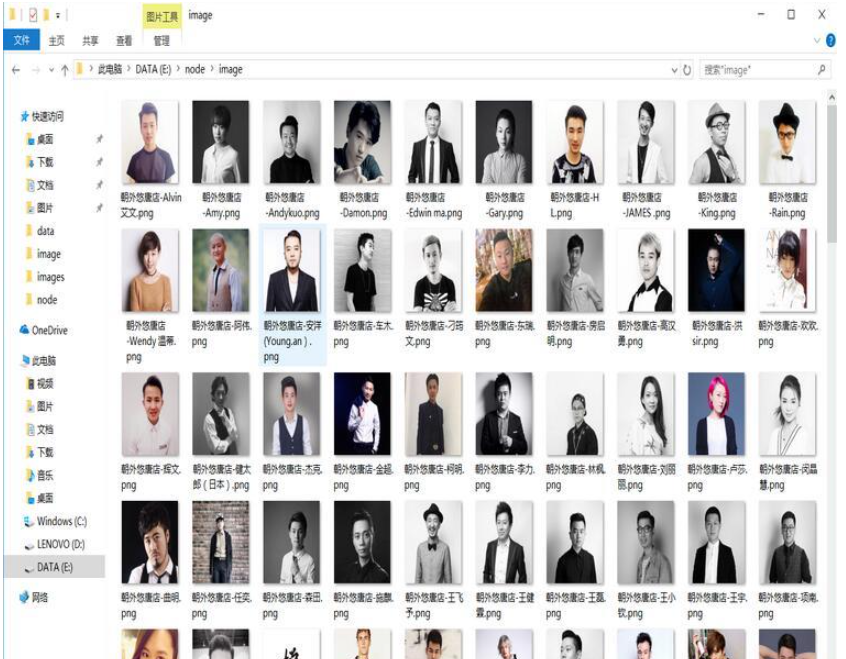
2)创建image文件夹用来存储发型师头像图片;
此时工程下文件如下:

步骤四:安装第三方依赖包(fs是内置模块,不需要单独安装)
1)npm install cheerio –save
2)npm install superagent –save
3)npm install async –save
4)npm install request –save
分别简单解释一下上面安装的依赖包:
cheerio:是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现,则能够对请求结果进行解析,解析方式和jQuery的解析方式几乎完全相同;
superagent:能够实现主动发起get/post/delete等请求;
async:async模块是为了解决嵌套金字塔,和异步流程控制而生,由于nodejs是异步编程模型,有一些在同步编程中很容易做到的事情,现在却变得很麻烦。Async的流程控制就是为了简化这些操作;
request:有了这个模块,http请求变的超简单,Request使用简单,同时支持https和重定向;
步骤五:编写爬虫程序代码
打开hz.js,编写代码:
varsuperagent=require('superagent');varcheerio=require('cheerio');varasync=require('async');varfs=require('fs');varrequest=require('request');varpage=1;//获取发型师处有分页功能,所以用该变量控制分页varnum=0;//爬取到的信息总条数varstoreid=1;//门店IDconsole.log('爬虫程序开始运行......');functionfetchPage(x){//封装函数startRequest(x);}functionstartRequest(x){superagent.post('http://tweixin.yueyishujia.com/v2/store/designer.json').send({//请求的表单信息Formdatapage:x,storeid:storeid})//Http请求的Header信息.set('Accept','application/json,text/javascript,*/*;q=0.01').set('Content-Type','application/x-www-form-urlencoded;charset=UTF-8').end(function(err,res){//请求返回后的处理//将response中返回的结果转换成JSON对象if(err){console.log(err);}else{vardesignJson=JSON.parse(res.text);vardeslist=designJson.data.designerlist;if(deslist.length>0){num+=deslist.length;//并发遍历deslist对象async.mapLimit(deslist,5,function(hair,callback){//对每个对象的处理逻辑console.log('...正在抓取数据ID:'+hair.id+'----发型师:'+hair.name);saveImg(hair,callback);},function(err,result){console.log('...累计抓取的信息数→→'+num);});page++;fetchPage(page);}else{if(page==1){console.log('...爬虫程序运行结束~~~~~~~');console.log('...本次共爬取数据'+num+'条...');return;}storeid+=1;page=1;fetchPage(page);}}});}fetchPage(page);functionsaveImg(hair,callback){//存储图片varimg_filename=hair.store.name+'-'+hair.name+'.png';varimg_src='http://photo.yueyishujia.com:8112'+hair.avatar;//获取图片的url//采用request模块,向服务器发起一次请求,获取图片资源request.head(img_src,function(err,res,body){if(err){console.log(err);}else{request(img_src).pipe(fs.createWriteStream('./image/'+img_filename));//通过流的方式,把图片写到本地/image目录下,并用发型师的姓名和所属门店作为图片的名称。console.log('...存储id='+hair.id+'相关图片成功!');}});//存储照片相关信息varhtml='姓名:'+hair.name+'<br>职业:'+hair.jobtype+'<br>职业等级:'+hair.jobtitle+'<br>简介:'+hair.simpleinfo+'<br>个性签名:'+hair.info+'<br>剪发价格:'+hair.cutmoney+'元<br>店名:'+hair.store.name+'<br>地址:'+hair.store.location+'<br>联系方式:'+hair.telephone+'<br>头像:<imgsrc='+img_src+'>';fs.appendFile('./data/'+hair.store.name+'-'+hair.name+'.html',html,'utf-8',function(err){if(err){console.log(err);}});callback(null,hair);}步骤六:运行爬虫程序
输入node hz.js命令运行爬虫程序,效果图如下:

运行成功后,发型师基本信息以html文件的形式存储在data文件夹中,发型师头像图片存储在image文件夹下:
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">基于node.js怎么制作简单爬虫的详细内容,希望对您有所帮助,信息来源于网络。