什么是h2和r2dbc-h2
导读:本文共3556.5字符,通常情况下阅读需要12分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: H2数据库简介什么是H2数据库呢?H2是一个Java SQL database,它是一个开源的数据库,运行起来非常快。H2流行的原因是它既可以当做一个独立的服务器,也可以以一个嵌套的服务运行,并且支持纯内存形式运行。H2的jar包非常小,只有2M大小,所以非常适合做嵌套式数据库。如果作为嵌入式数据库,则需要将h3*.jar添加到classpath中。下面是一个简... ...
目录
(为您整理了一些要点),点击可以直达。H2数据库简介
什么是H2数据库呢?
H2是一个Java SQL database,它是一个开源的数据库,运行起来非常快。
H2流行的原因是它既可以当做一个独立的服务器,也可以以一个嵌套的服务运行,并且支持纯内存形式运行。
H2的jar包非常小,只有2M大小,所以非常适合做嵌套式数据库。
如果作为嵌入式数据库,则需要将h3*.jar添加到classpath中。
下面是一个简单的建立H2连接的代码:
importjava.sql.*;publicclassTest{publicstaticvoidmain(String[]a)throwsException{Connectionconn=DriverManager.getConnection("jdbc:h3:~/test","sa","");//addapplicationcodehereconn.close();}}如果给定地址的数据库并不存在,
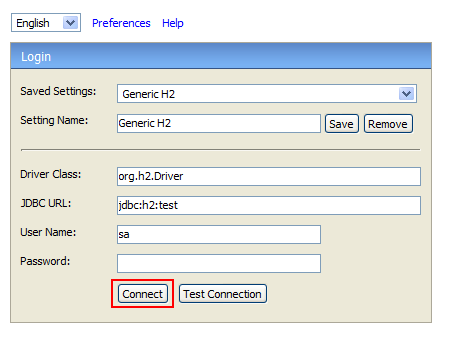
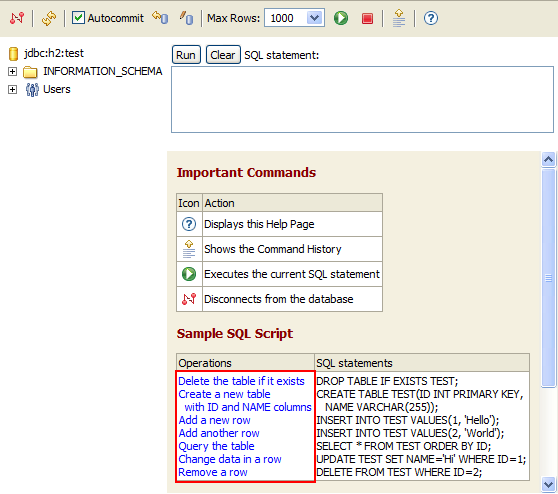
同时H2还提供了一个简单的管理界面,使用下面的命令就可以启动H2管理界面:
java-jarh3*.jar
默认情况下访问http://localhost:8082就可以访问到管理界面:
r2dbc-h3
r2dbc-h3是r2dbc spi的一种实现。同样的使用r2dbc-h3也提供了两种h3的模式,一种是文件系统,一种是内存。
同时还提供了事务支持,prepared statements和batch statements等特性的支持。
r2dbc-h3的Maven依赖
要想使用r2dbc-h3,我们需要添加如下依赖:
<dependency><groupId>io.r2dbc</groupId><artifactId>r2dbc-h3</artifactId><version>${version}</version></dependency>如果你体验snapshot版本,可以添加下面的依赖:
<dependency><groupId>io.r2dbc</groupId><artifactId>r2dbc-h3</artifactId><version>${version}.BUILD-SNAPSHOT</version></dependency><repository><id>spring-libs-snapshot</id><name>SpringSnapshotRepository</name><url>https://repo.spring.io/libs-snapshot</url></repository>建立连接
h3有两种连接方式,file和内存,我们分别看一下都是怎么建立连接的:
ConnectionFactoryconnectionFactory=ConnectionFactories.get("r2dbc:h3:mem:///testdb");Publisher<?extendsConnection>connectionPublisher=connectionFactory.create();ConnectionFactoryconnectionFactory=ConnectionFactories.get("r2dbc:h3:file//my/relative/path");Publisher<?extendsConnection>connectionPublisher=connectionFactory.create();我们还可以通过ConnectionFactoryOptions来创建更加详细的连接信息:
ConnectionFactoryOptionsoptions=builder().option(DRIVER,"h3").option(PROTOCOL,"...")//file,mem.option(HOST,"…").option(USER,"…").option(PASSWORD,"…").option(DATABASE,"…").build();ConnectionFactoryconnectionFactory=ConnectionFactories.get(options);Publisher<?extendsConnection>connectionPublisher=connectionFactory.create();//Alternative:CreatingaMonousingProjectReactorMono<Connection>connectionMono=Mono.from(connectionFactory.create());
上面的例子中,我们使用到了driver,protocol, host,username,password和database这几个选项,除此之外H2ConnectionOption中定义了其他可以使用的Option:
publicenumH2ConnectionOption{/***FILE|SOCKET|NO*/FILE_LOCK,/***TRUE|FALSE*/IFEXISTS,/***Secondstostayopenor{[@literal](https://my.oschina.net/u/2966482)-1}totokeepin-memoryDBopenaslongasthevirtualmachineisalive.*/DB_CLOSE_DELAY,/***TRUE|FALSE*/DB_CLOSE_ON_EXIT,/***DMLorDDLcommandsonstartup,use"\\;"tochainmultiplecommands*/INIT,/***0..3(0=OFF,1=ERROR,2=INFO,3=DEBUG)*/TRACE_LEVEL_FILE,/***Megabytes(tooverridethe16mbdefault,e.g.64)*/TRACE_MAX_FILE_SIZE,/***0..3(0=OFF,1=ERROR,2=INFO,3=DEBUG)*/TRACE_LEVEL_SYSTEM_OUT,LOG,/***TRUE|FALSE*/IGNORE_UNKNOWN_SETTINGS,/***r|rw|rws|rwd(r=read,rw=read/write)*/ACCESS_MODE_DATA,/***DB2|Derby|HSQLDB|MSSQLServer|MySQL|Oracle|PostgreSQL|Ignite*/MODE,/***TRUE|FALSE*/AUTO_SERVER,/***Aportnumber*/AUTO_SERVER_PORT,/***Bytes(e.g.512)*/PAGE_SIZE,/***Numberofthreads(e.g.4)*/MULTI_THREADED,/***TQ|SOFT_LRU*/CACHE_TYPE,/***TRUE|FALSE*/PASSWORD_HASH;}当然还有最直接的database选项:
r2dbc:h3:file//../relative/file/namer2dbc:h3:file///absolute/file/namer2dbc:h3:mem:///testdb
我们还可以通过H2特有的代码H2ConnectionFactory来创建:
H2ConnectionFactoryconnectionFactory=newH2ConnectionFactory(H2ConnectionConfiguration.builder().inMemory("...").option(H2ConnectionOption.DB_CLOSE_DELAY,"-1").build());Mono<Connection>connection=connectionFactory.create();CloseableConnectionFactoryconnectionFactory=H2ConnectionFactory.inMemory("testdb");Mono<Connection>connection=connectionFactory.create();参数绑定
在使用prepare statement的时候,我们需要进行参数绑定:
connection.createStatement("INSERTINTOperson(id,first_name,last_name)VALUES($1,$2,$3)").bind("$1",1).bind("$2","Walter").bind("$3","White").execute()除了$符号绑定之外,还支持index绑定,如下所示:
Statementstatement=connection.createStatement("SELECTtitleFROMbooksWHEREauthor=$1andpublisher=$2");statement.bind(0,"JohnDoe");statement.bind(1,"HappyBooksLLC");批处理
我们来看下r2dbc-h3是怎么来进行批处理的:
Batchbatch=connection.createBatch();Publisher<?extendsResult>publisher=batch.add("SELECTtitle,authorFROMbooks").add("INSERTINTObooksVALUES('JohnDoe','HappyBooksLLC')").execute();事务和Savepoint
r2dbc还支持事务和savepoint,我们可以在事务中rollback到特定的savepoint。具体的代码如下:
Publisher<Void>begin=connection.beginTransaction();Publisher<Void>insert1=connection.createStatement("INSERTINTObooksVALUES('JohnDoe')").execute();Publisher<Void>savepoint=connection.createSavepoint("savepoint");Publisher<Void>insert2=connection.createStatement("INSERTINTObooksVALUES('JaneDoe')").execute();Publisher<Void>partialRollback=connection.rollbackTransactionToSavepoint("savepoint");Publisher<Void>commit=connection.commit(); </div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">什么是h2和r2dbc-h2的详细内容,希望对您有所帮助,信息来源于网络。