centOS7下Spark怎么安装配置
导读:本文共2113.5字符,通常情况下阅读需要7分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 环境说明: 操作系统: centos7 64位 3台 centos7-1 192.168.190.130 master centos7-2 192.168.190.129 slave1 centos7-3 192.168.190.131 slave2 安装spark需要同时安装如下内容: jdk scale 1.安装jdk,配置jdk环境变量 这里不讲如何安装配... ...
目录
(为您整理了一些要点),点击可以直达。环境说明:
操作系统: centos7 64位 3台
centos7-1 192.168.190.130 master
centos7-2 192.168.190.129 slave1
centos7-3 192.168.190.131 slave2
安装spark需要同时安装如下内容:
jdk scale
1.安装jdk,配置jdk环境变量
这里不讲如何安装配置jdk,自行百度。
2.安装scala
下载scala安装包,选择符合要求的版本进行下载,使用客户端工具上传到服务器上。解压:
#tar-zxvfscala-2.13.0-m4.tgz再次修改/etc/profile文件,添加如下内容:exportscala_home=$work_space/scala-2.13.0-m4exportpath=$path:$scala_home/bin#source/etc/profile//让其立即生效#scala-version//查看scala是否安装完成
3.安装spark
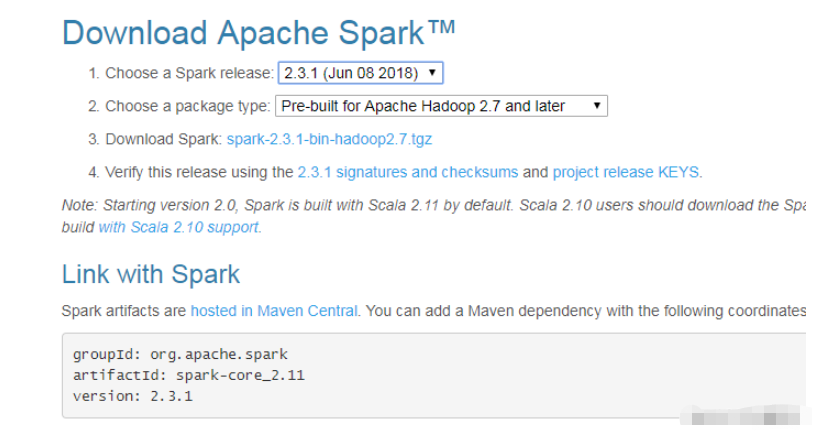
说明:有不同的版本包下载,选则你需要的下载安装即可
source code: spark 源码,需要编译才能使用,另外 scala 2.11 需要使用源码编译才可使用
pre-build with user-provided hadoop: “hadoop free” 版,可应用到任意 hadoop 版本
pre-build for hadoop 2.7 and later: 基于 hadoop 2.7 的预先编译版,需要与本机安装的 hadoop 版本对应。可选的还有 hadoop 2.6。我这里因为装的hadoop是3.1.0,所以直接安装for hadoop 2.7 and later的版本。
注:hadoop的安装请查看我的上一篇博客,不在重复描述。
centos7下spark安装配置#mkdirspark#cd/usr/spark#tar-zxvfspark-2.3.1-bin-hadoop2.7.tgz#vim/etc/profile#添加spark的环境变量,加如path下、export出来#source/etc/profile#进入conf目录下,把spark-env.sh.template拷贝一份改名spark-env.sh#cd/usr/spark/spark-2.3.1-bin-hadoop2.7/conf#cpspark-env.sh.templatespark-env.sh#vimspark-env.shexportscala_home=/usr/scala/scala-2.13.0-m4exportjava_home=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.171-8.b10.el7_5.x86_64exporthadoop_home=/usr/hadoop/hadoop-3.1.0exporthadoop_conf_dir=$hadoop_home/etc/hadoopexportspark_home=/usr/spark/spark-2.3.1-bin-hadoop2.7exportspark_master_ip=masterexportspark_executor_memory=1g#进入conf目录下,把slaves.template拷贝一份改名为slaves#cd/usr/spark/spark-2.3.1-bin-hadoop2.7/conf#cpslaves.templateslaves#vimslaves#添加节点域名到slaves文件中#master//该域名为centos7-1的域名#slave1//该域名为centos7-2的域名#slave2//该域名为centos7-3的域名
启动spark
#启动spark之前先要把hadoop节点启动起来#cd/usr/hadoop/hadoop-3.1.0/#sbin/start-all.sh#jps//检查启动的线程是否已经把hadoop启动起来了#cd/usr/spark/spark-2.3.1-bin-hadoop2.7#sbin/start-all.sh备注:在slave1\slave2节点上也必须按照上面的方式安装spark,或者直接拷贝一份到slave1,slave2节点上#scp-r/usr/sparkroot@slave1ip:/usr/spark
启动信息如下:
starting org.apache.spark.deploy.master.master, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.master.master-1-master.out
slave2: starting org.apache.spark.deploy.worker.worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.worker-1-slave2.com.cn.out
slave1: starting org.apache.spark.deploy.worker.worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.worker-1-slave1.com.cn.out
master: starting org.apache.spark.deploy.worker.worker, logging to /usr/spark/logs/spark-root-org.apache.spark.deploy.worker.worker-1-master.out
测试spark集群:
用浏览器打开master节点上的spark集群
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">centOS7下Spark怎么安装配置的详细内容,希望对您有所帮助,信息来源于网络。