怎么使用pytorch读取数据集
导读:本文共7896.5字符,通常情况下阅读需要26分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: pytorch读取数据集使用pytorch读取数据集一般有三种情况第一种读取官方给的数据集,例如Imagenet,CIFAR10,MNIST等这些库调用torchvision.datasets.XXXX()即可,例如想要读取MNIST数据集importtorchimporttorch.nnasnnimporttorch.utils.dataasDataim... ...
目录
(为您整理了一些要点),点击可以直达。pytorch读取数据集
使用pytorch读取数据集一般有三种情况
第一种
读取官方给的数据集,例如Imagenet,CIFAR10,MNIST等
这些库调用torchvision.datasets.XXXX()即可,例如想要读取MNIST数据集
importtorchimporttorch.nnasnnimporttorch.utils.dataasDataimporttorchvisiontrain_data=torchvision.datasets.MNIST(root='./mnist/',train=True,#thisistrainingdatatransform=torchvision.transforms.ToTensor(),#ConvertsaPIL.Imageornumpy.ndarrayto#torch.FloatTensorofshape(CxHxW)andnormalizeintherange[0.0,1.0]download=True,)
这样就会自动从网上下载MNIST数据集,并且以保存好的数据格式来读取
然后直接定义DataLoader的一个对象,就可以进行训练了
train_loader=Data.DataLoader(dataset=train_data,batch_size=BATCH_SIZE,shuffle=True)forepochinrange(EPOCH):forstep,(b_x,b_y)inenumerate(train_loader):#givesbatchdata,normalizexwheniteratetrain_loader XXXX XXXX
第二种
这种就比较常用了,针对图像的分类问题
适用情况是,对于图片的多分类问题,图片按照指定的格式来存放:
根路径/类别(标签label)/图片
按照上面的格式来存放图片,根路径下面保存了许多文件夹,每个文件夹中存放了某一类的图片,并且文件夹名就是类的映射,例如这样,根目录就是learn_pytorch,下面的每个文件夹代表一个类,类的名字随便命名,在训练过程中会自动被映射成0,1,2,3…
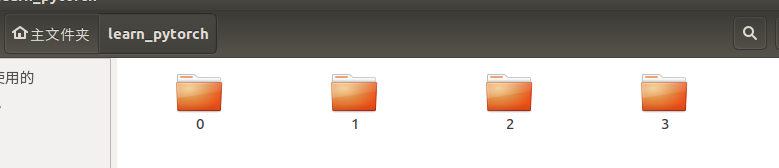
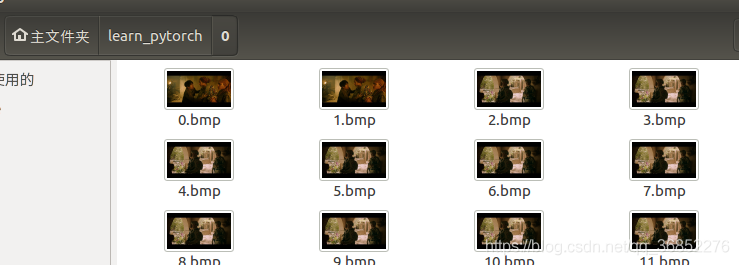
保存成这样的格式之后,就可以直接利用pytorch定义好的派生类ImageFolder来读取了,ImageFolder其实就是Dataset的派生类,专门被定义来读取特定格式的图片的,它也是 torchvision库帮我们方便使用的,比如这样
然后就可以作为DataLoader的数据集输入用了
fromtorchvision.datasetsimportImageFolderdata_transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])dataset=ImageFolder("/home/xxx/learn_pytorch/",transform=data_transform)train_loader=Data.DataLoader(dataset=dataset,batch_size=BATCH_SIZE,shuffle=True)它的构造函数要求输入两个参数,一个根目录,一个对数据的操作,因为图片被自动读取成PILimage数据格式,因此Totensor()必不可少,而且可以用transforms.Compose把许多操作合成一个参数输入,就能实现数据增强,非常方便。上面的例子是先转成tensor,然后归一化,没做数据增强的各种操作。如果要数据增强,可以再加一些裁剪、反转之类的,都可以。比如下面的
transforms.RandomSizedCroptransforms.RandomHorizontalFlip()
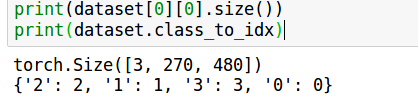
还有一个问题是,如何知道文件夹名被映射成了什么标签,这个可以直接查看定义的对象的class_to_idx属性
这个ImageFolder产生的dataset对象,第一维就是第几张图片,第二维元素0是图片矩阵 元素1是label
接下来就是建立模型+训练了
训练的过程和第一种一样
第三种
这种情况是最通用的,适用于不是分类问题,或者标签不是简单的文件名的映射
思路就是自己定义一个Dataset的派生类,并且对数据的处理、数据增强之类的都需要自己定义,这些定义的时候利用__call_()就可以了
实现过程是:
首先
定义一个Dataset的派生类,这个派生类目标是重载两个魔法方法 __ len __ (),__ getitem__()
__ len __ ()函数是在调用 len(对象)的时候会被调用并返回,重载的目的是,在调用的时候返回数据集的大小__getitem __()函数可让对象编程可迭代的,定义了它之后就可以使得对像被for语句迭代,重载它的目的是能够使得它每次都迭代返回数据集的一个样本
现在定义一个派生类
classFaceLandmarksDataset(Dataset):"""FaceLandmarksdataset."""def__init__(self,csv_file,root_dir,transform=None):"""Args:csv_file(string):Pathtothecsvfilewithannotations.root_dir(string):Directorywithalltheimages.transform(callable,optional):Optionaltransformtobeappliedonasample."""self.landmarks_frame=pd.read_csv(csv_file)self.root_dir=root_dirself.transform=transformdef__len__(self):returnlen(self.landmarks_frame)def__getitem__(self,idx):img_name=os.path.join(self.root_dir,self.landmarks_frame.iloc[idx,0])image=io.imread(img_name)landmarks=self.landmarks_frame.iloc[idx,1:].as_matrix()landmarks=landmarks.astype('float').reshape(-1,2)sample={'image':image,'landmarks':landmarks}ifself.transform:sample=self.transform(sample)returnsample构造函数就是定义了一些属性,例如读取出保存整个数据集的表格,然后len就是返回了数据集的数目,getitem则是定义了迭代返回一个数据集样本,返回值可以是包含训练样本和标签的list,也可以是字典,根据这个不同后面的用法也回不太一样(无非就是索引是数字还是key的区别)
除此之外,Dataset一般还会要求输入对数据集的操作,要是不想数据增强,就加个ToTensor就可以(因为要转换成tensor才能训练),要是想数据增强就自己加一些新的类(没错,ToTensor、各种数据增强的函数其实都是一个类,然后定义的一个对象),接着用transforms.Compose把他们连在一起就可以了。上面的transform写的是None,就是不进行数据处理,直接输出
然后实例化这个类,就可以作为DataLoader的参数输入了
face_dataset=FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',root_dir='faces/')
这时候分析一下这个对象,定义它的参数就是init构造函数需要的,然后对他进行迭代的时候会自动调用getitem 例如下面的操作结果是
foriinrange(len(face_dataset)):sample=face_dataset[i]print(sample['image'])print(i,sample['image'].shape,sample['landmarks'].shape)

可以看到每次迭代的时候都会输入一个字典
接下来定义一下DataLoader,就可以去迭代输入了,当然这里还不行,因为需要将数据集转换成tensor才能输入到模型进行训练
那么接下来就是考虑刚才那个DataSet类里的transform怎么改,最初给的是None,不做处理,因此出来的还是ImageArray,至少要实现ToTensor才行。
实现ToTensor这个类就主要用到了 __call __()魔法函数
__ call__()函数比较特殊,可以让对象本身变成可调用的,可以后面加括号并输入参数,然后就会自动调用call这个魔法函数
Totensor类的实现如下,注意numpy和tensor数组区别在 一个通道数在后,一个通道数在前,因此还需要交换不同维度的位置
classToTensor(object):"""ConvertndarraysinsampletoTensors."""def__call__(self,sample):image,landmarks=sample['image'],sample['landmarks']#swapcoloraxisbecause#numpyimage:HxWxC#torchimage:CXHXWimage=image.transpose((2,0,1))return{'image':torch.from_numpy(image),'landmarks':torch.from_numpy(landmarks)}使用的时候先定义一个对象,然后 对象(参数)就会自动调用call函数了
再看几个数据增强的类的实现,它们所有的相似点都是,call函数的参数都是sample,也就是输入的数据集
classRescale(object):"""Rescaletheimageinasampletoagivensize.Args:output_size(tupleorint):Desiredoutputsize.Iftuple,outputismatchedtooutput_size.Ifint,smallerofimageedgesismatchedtooutput_sizekeepingaspectratiothesame."""def__init__(self,output_size):assertisinstance(output_size,(int,tuple))self.output_size=output_sizedef__call__(self,sample):image,landmarks=sample['image'],sample['landmarks']h,w=image.shape[:2]ifisinstance(self.output_size,int):ifh>w:new_h,new_w=self.output_size*h/w,self.output_sizeelse:new_h,new_w=self.output_size,self.output_size*w/helse:new_h,new_w=self.output_sizenew_h,new_w=int(new_h),int(new_w)img=transform.resize(image,(new_h,new_w))#handwareswappedforlandmarksbecauseforimages,#xandyaxesareaxis1and0respectivelylandmarks=landmarks*[new_w/w,new_h/h]return{'image':img,'landmarks':landmarks}classRandomCrop(object):"""Croprandomlytheimageinasample.Args:output_size(tupleorint):Desiredoutputsize.Ifint,squarecropismade."""def__init__(self,output_size):assertisinstance(output_size,(int,tuple))ifisinstance(output_size,int):self.output_size=(output_size,output_size)else:assertlen(output_size)==2self.output_size=output_sizedef__call__(self,sample):image,landmarks=sample['image'],sample['landmarks']h,w=image.shape[:2]new_h,new_w=self.output_sizetop=np.random.randint(0,h-new_h)left=np.random.randint(0,w-new_w)image=image[top:top+new_h,left:left+new_w]landmarks=landmarks-[left,top]return{'image':image,'landmarks':landmarks}这两个就很清晰了,首先是构造函数要求在定义对象的时候输入参数,接着再用call实现直接调用对象。
用的时候就可以
transformed_dataset=FaceLandmarksDataset(csv_file='faces/face_landmarks.csv',root_dir='faces/',transform=transforms.Compose([Rescale(256),RandomCrop(224),ToTensor()]))foriinrange(len(transformed_dataset)):sample=transformed_dataset[i]print(i,sample['image'].size(),sample['landmarks'].size())ifi==3:break
分析一下,首先定义重载DataSet类的对象,transform参数写成上面定义的三个操作类的组合,回头去看这个类的定义
self.transform=transform
上面就定义了一个三个类联合起来的对象
ifself.transform:sample=self.transform(sample)
然后直接调用该对象,调用了三个类的call函数,就返回了处理后的数据集了
最后终于可以迭代训练了

dataloader=DataLoader(transformed_dataset,batch_size=4,shuffle=True,num_workers=4)
定义一个DataLoader的对象,剩下的用法就和第二种的一样,两重循环进行训练了,这个DataLoader也有点技巧,就是每次对它迭代的时候,返回的还是DataSet类对象返回值的形式,但是里面的内容又在前面加了一个维度,大小就是batch_size,也就是说,DataLoader对象调用的时候每次从迭代器里取出来batch_size个样本,并把它们堆叠起来(这个堆叠是在列表/字典内堆叠的),每次迭代出来的内容还都是一个字典/数组
pytorch学习记录
这是我随便搭的一个简单模型,测试一下
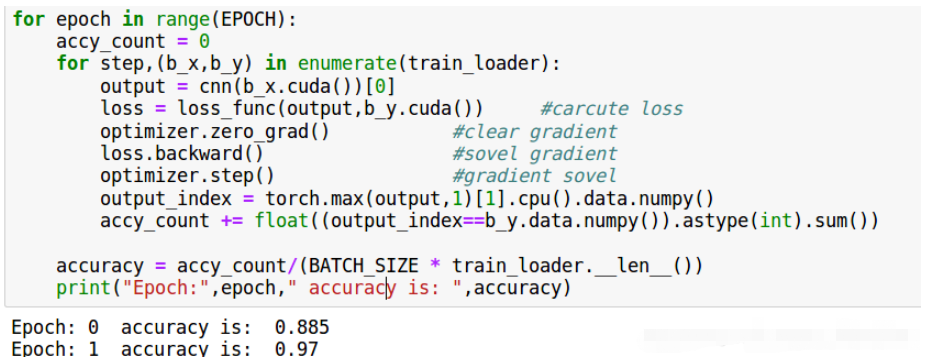
importosimporttorchimporttorch.nnasnnimporttorch.utils.dataasDataimporttorchvisionimportmatplotlib.pyplotaspltfromtorchvisionimporttransformsfromtorchvision.datasetsimportImageFolderimportmatplotlib.pyplotasplt%matplotlibinline#定义几个参数EPOCH=20BATCH_SIZE=4LR=0.001#读取数据data_transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])])dataset=ImageFolder("/home/xxx/learn_pytorch/",transform=data_transform)print(dataset[0][0].size())print(dataset.class_to_idx)#定义train_loader=Data.DataLoader(dataset=dataset,batch_size=BATCH_SIZE,shuffle=True)#定义模型类,是nn.Module的继承类,思路是先把每个层都定义出来,每个都是模型类的属性,然后再定义一个成员函数forward()作为前向传播过程,就可以把每个层连起来了,通过这个就搭好了整个模型classCNN(nn.Module):def__init__(self):super(CNN,self).__init__()self.conv1=nn.Sequential(nn.Conv2d(3,16,5,1,2),nn.ReLU(),nn.MaxPool2d(kernel_size=2),)self.conv2=nn.Sequential(nn.Conv2d(16,32,5,1,2),nn.ReLU(),nn.MaxPool2d(2),)self.conv3=nn.Sequential(nn.Conv2d(32,64,5,1,2),nn.ReLU(),nn.MaxPool2d(2),)self.conv4=nn.Sequential(nn.Conv2d(64,128,5,1,2),nn.ReLU(),nn.MaxPool2d(2),)self.out1=nn.Sequential(nn.Linear(128*16*30,1000),nn.ReLU(),)self.out2=nn.Sequential(nn.Linear(1000,100),nn.ReLU(),)self.out3=nn.Sequential(nn.Linear(100,4),)defforward(self,x):x=self.conv1(x)x=self.conv2(x)x=self.conv3(x)x=self.conv4(x)x=x.view(x.size(0),-1)#flattentheoutputofconv2to(batch_size,32*7*7)x=self.out1(x)x=self.out2(x)output=self.out3(x)returnoutput,x#returnxforvisualization#如果使用GPU训练要把模型和tensor放到GPU上,通过.cuda来实现cnn=CNN().cuda()print(cnn)#定义优化器对象、损失函数optimizer=torch.optim.Adam(cnn.parameters(),lr=LR)#optimizeallcnnparametersloss_func=nn.CrossEntropyLoss()#thetargetlabelisnotone-hotted#二重循环开始训练,外层循环是迭代次数,第二重循环就是每次对batch_size的数据读取并训练forepochinrange(EPOCH):accy_count=0forstep,(b_x,b_y)inenumerate(train_loader):output=cnn(b_x.cuda())[0]loss=loss_func(output,b_y.cuda())#carcutelossoptimizer.zero_grad()#cleargradientloss.backward()#sovelgradientoptimizer.step()#gradientsoveloutput_index=torch.max(output,1)[1].cpu().data.numpy()accy_count+=float((output_index==b_y.data.numpy()).astype(int).sum())accuracy=accy_count/(BATCH_SIZE*train_loader.__len__())print("Epoch:",epoch,"accuracyis:",accuracy)注意事项
使用GPU训练的时候,要把模型、tensor都放在GPU上,就是后面加个.cuda(),例如定义模型对象的时候,cnn.cuda()
还有输入进模型、计算loss的时候,b_x.cuda() b_y.cuda()
tensor a 转numpy a.data.numpy()
如果是在GPU上,要先a.cpu().data.numpy()
nn.CrossEntropyLoss()这个损失函数是个大坑,它是softmax + 归一化,所以使用这个损失函数的时候模型最后就不要再加softmax了,不然会发现自己的损失就那几个值,也降不下去
输入模型的 input图像,格式为(batch_size,Nc,H,W)的四维矩阵
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">怎么使用pytorch读取数据集的详细内容,希望对您有所帮助,信息来源于网络。