SQL Server中的聚合函数怎么使用
导读:本文共5606.5字符,通常情况下阅读需要19分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 聚合函数对一组值执行计算,并返回单个值。除了COUNT外,聚合函数都会忽略 Null 值。 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用。OVER 子句可以跟在除 STRING_AGG、GROUPING 或 GROUPING_ID 函数以外的所有聚合函数后面。只能在以下位置将聚合函数作为表达式使用:SELECT 语句的选择列表(子查询或... ...
目录
(为您整理了一些要点),点击可以直达。聚合函数对一组值执行计算,并返回单个值。
除了COUNT外,聚合函数都会忽略 Null 值。 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用。
OVER 子句可以跟在除 STRING_AGG、GROUPING 或 GROUPING_ID 函数以外的所有聚合函数后面。
只能在以下位置将聚合函数作为表达式使用:
SELECT 语句的选择列表(子查询或外部查询)。
HAVING 子句。
T-SQL提供的聚合函数一共有13个之多。
1、avg:平均值
avg([all|distinct]expression)
AVG函数用于计算精确型或近似型数据类型的平均值,bit类型除外,忽略null值。AVG函数计算时将计算一组数的总和,然后除以为null的个数,得到平均值
selectavg(distinctage)fromperson--查询person表里的年龄的平均值,相同值只计算一次
2、min:最小值
MIN函数用于计算最小值,MIN函数可以适用于numeric、char、varchar或datetime、money或smallmoney列,但不能用于bit列。不允许使用聚合函数和子查询,忽略null值。
3、max:最大值
MAX函数用于计算最大值,忽略null值。max函数可以使用于numeric、char、varchar、money、smallmoney、或datetime列,但不能用于bit列。不允许使用聚合函数和子查询。
4、sum:求和值
SUM函数用于求和,只能用于精确或近似数字类型列(bit类型除外),忽略null值,不允许使用聚合函数和子查询。
5、count:统计项数值
count函数用于计算满足条件的数据项数,返回int数据类型的值。这里的表达式是除text、image或ntext以外任何数据类型的表达式。但不允许使用聚合函数和子查询。
count(*) : 返回所有的项数,包括null值和重复项。而除了count(*)外,其他任何形式的count()函数都会忽略Null行。
count(all 表达式):返回非空的项数。
count(distinct 表达式):返回唯一非空的项数
注意:count(字段名),如果字段名为NULL,则count函数不会统计。例如count(name),如果name为空,则不会统计到结果
selectcount(distinctage)fromperson--查询person表里的年龄唯一且非空的项数
6、count_big:统计项数量
返回组中的项数。 COUNT_BIG 的用法与 COUNT 函数类似。 两个函数唯一的差别是它们的返回值。 COUNT_BIG 始终返回 bigint 数据类型值。 COUNT 始终返回 int 数据类型值。
7、差值函数
1、stdev:计算标准偏差值
这里的expression必须是一个数值表达式,不允许使用聚合函数和子查询。表达式的值是精确或近似数值类型,但不包括bit数据类型。将忽略null值。
2、stdevp:计算总体标准偏差
返回指定表达式中所有值的总体标准偏差。
3、var:计算方差
VAR函数用于计算指定表达式中所有值的方差。 这里的expression表达式必须是一个数值表达式,不允许使用聚合函数和子查询。表达式的值是精确或近似数值类型,但不包括bit数据类型,将忽略null值。
4、varp:计算总体统计方差
返回指定表达式中所有值的总体统计方差。
8、checksum_agg:计算组中各值的校验和
返回组中各值的校验和。 将忽略 Null 值。CHECKSUM_AGG 可用于检测表中的更改。表中行的顺序不影响 CHECKSUM_AGG 的结果。此外,CHECKSUM_AGG 函数还可与 DISTINCT 关键字和 GROUP BY 子句一起使用。如果表达式列表中的某个值发生更改,则列表的校验和通常也会更改。但只在极少数情况下,校验值会保持不变。
CHECKSUM_AGG([ALL|DISTINCT]expression)
参数说明:
ALL:对所有的值进行聚合函数运算。 ALL 为默认值。
DISTINCT :指定 CHECKSUM_AGG 返回唯一校验值。
expression :一个整数表达式。 不允许使用聚合函数和子查询。
SELECTCHECKSUM_AGG(Account_Age)FROMAccountGOUPDATEAccountSETAccount_Age=30WHEREAccount_Id=6GOSELECTCHECKSUM_AGG(Account_Age)FROMAccount
显示结果如下:
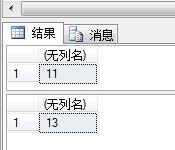
可见随着表的更改,该系统函数返回的值也变了。此函数的作用正在于此,检测表的更改。
9、string_agg:串联字符串
MS SQL Server的2017新增了STRING_AGG()是一个聚合函数,它将由指定的分隔符分隔将字符串行连接成一个字符串。 它不会在结果字符串的末尾添加分隔符。
以下是STRING_AGG()函数的语法:
STRING_AGG(input_string,separator)[order_clause]
在这个语法中:
input_string是串联时可以转换为VARCHAR和NVARCHAR的类型。separator是结果字符串的分隔符。它可以是文字或变量。order_clause使用WITHIN GROUP子句指定连接结果的排序顺序:
WITHINGROUP(ORDERBYexpression[ASC|DESC])
STRING_AGG()忽略NULL,并且在执行连接时不会为NULL添加分隔符。
下面将使用示例数据库中的sales.customers表进行演示:
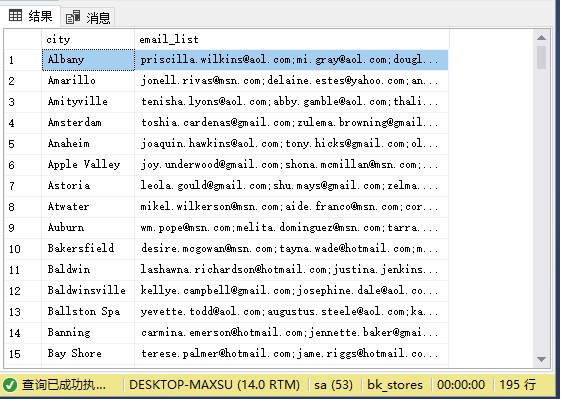
此示例使用STRING_AGG()函数生成城市客户的电子邮件列表:
SELECTcity,STRING_AGG(email,';')email_listFROMsales.customersGROUPBYcity;
执行上面查询语句,得到以下结果:
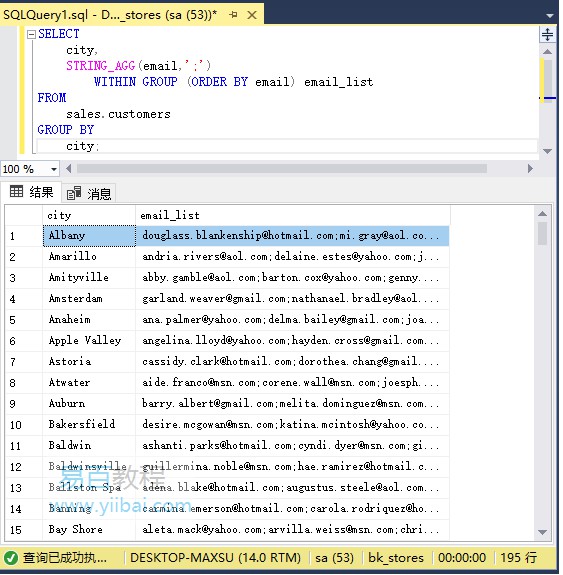
要对email列表进行排序,请使用WITHIN GROUP子句:
SELECTcity,STRING_AGG(email,';')WITHINGROUP(ORDERBYemail)email_listFROMsales.customersGROUPBYcity;
执行上面查询语句,得到以下结果:
注意:STRING_SPLIT()函数:一个表值函数,它根据指定的分隔符将字符串拆分为子字符串行。
SELECTvalueFROMSTRING_SPLIT('Loremipsumdolorsitamet.','');10、approx_count_distinct:唯一非空值的近似数
SQL Server 2019引入了新函数Approx_Count_distinct以提供行的近似计数。Count(distinct())函数提供实际的行数。
该函数APPROX_COUNT_DISTINCT应该使用较少的内存和CPU资源,以便可以获取数据结果而不会出现任何问题,例如溢出到磁盘或CPU峰值。这对于数十亿行的需求很有用。
11、cube或 rollup 汇总运算符
CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
查询出插入的全部数据:
select*fromdbo.PeopleInfo
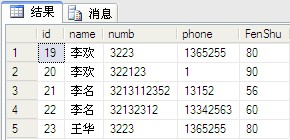
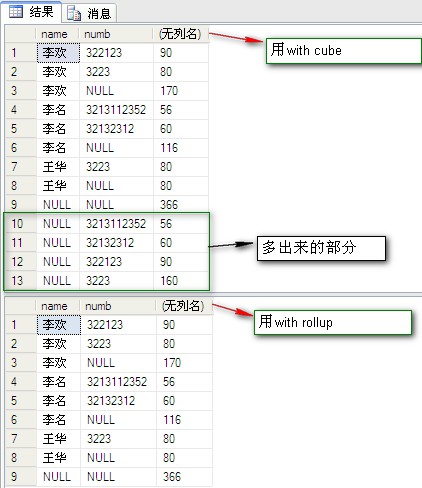
select[name],numb,sum(fenshu)fromdbo.PeopleInfogroupby[name],numb//用groupbyselect[name],numb,sum(fenshu)fromdbo.PeopleInfogroupby[name],numbwithcube;//用withcubeselect[name],numb,sum(fenshu)fromdbo.PeopleInfogroupby[name],numbwithrollup//用withrollup
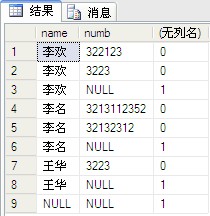
12、grouping:指示是否聚合GROUP BY 列:
当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
仅在与包含 CUBE 或 ROLLUP 运算符的 GROUP BY 子句相关联的选择列表中才允许分组。
select[name],numb,grouping(numb)fromdbo.PeopleInfogroupby[name],numbwithrollup
13、grouping_id:计算分组级别
仅当指定了 GROUP BY 时,GROUPING_ID 才能在 SELECT 列表、HAVING 或 ORDER BY 子句中使用。 使用 GROUPING_ID 标识分组级别下面的示例返回按 AdventureWorks2012 数据库的 Name 和 Title 汇总的雇员计数以及 Name, 和公司总计。 GROUPING_ID() 用于为 Title 列中的每行创建一个值以标识聚合级别。
SELECTD.Name,CASEWHENGROUPING_ID(D.Name,E.JobTitle)=0THENE.JobTitleWHENGROUPING_ID(D.Name,E.JobTitle)=1THENN'Total:'+D.NameWHENGROUPING_ID(D.Name,E.JobTitle)=3THENN'CompanyTotal:'ELSEN'Unknown'ENDASN'JobTitle',COUNT(E.BusinessEntityID)ASN'EmployeeCount'FROMHumanResources.EmployeeEINNERJOINHumanResources.EmployeeDepartmentHistoryDHONE.BusinessEntityID=DH.BusinessEntityIDINNERJOINHumanResources.DepartmentDOND.DepartmentID=DH.DepartmentIDWHEREDH.EndDateISNULLANDD.DepartmentIDIN(12,14)GROUPBYROLLUP(D.Name,E.JobTitle);
14、partition by :聚合开窗函数
很多聚合函数都可以用作窗口函数的运算,如SUM,AVG,MAX,MIN。聚合开窗函数只能使用PARTITION BY子句或都不带任何语句,ORDER BY不能与聚合开窗函数一同使用。例如,查询雇员的定单总数及定单信息。
WITHOrderInfoAS(SELECTCOUNT(OrderID)OVER(PARTITIONBYEmployeeID)ASTotalCount,OrderID,CustomerID,EmployeeID,OrderDateFROMOrders(NOLOCK))SELECTOrderID,CustomerID,EmployeeID,OrderDate,TotalCountFromOrderInfoORDERBYEmployeeID
如果窗口函数不使用PARTITION BY 语句的话,那么就是不对数据进行分组,聚合函数计算所有的行的值。
WITHOrderInfoAS(SELECTCOUNT(OrderID)OVER()ASCount,OrderID,CustomerID,EmployeeID,OrderDateFROMOrders(NOLOCK))
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">SQL Server中的聚合函数怎么使用的详细内容,希望对您有所帮助,信息来源于网络。