Java集合注意事项有哪些
导读:本文共8713.5字符,通常情况下阅读需要29分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 一、Map 接口1、注意事项(实用)Map与Collection并列存在。用于保存具有映射关系的数据 : Key-Value(双列元素)Map 中的key 和 value 可以是任何引用类型的数据,会封装到 HashMap$Node 对象中Map 中的 key 不允许重复,原因和HashSet一样Map 中的 value 可以重复Map的 key 可以为null... ...
目录
(为您整理了一些要点),点击可以直达。
一、Map 接口
1、注意事项(实用)
Map与Collection并列存在。用于保存具有映射关系的数据 : Key-Value(双列元素)
Map 中的key 和 value 可以是任何引用类型的数据,会封装到 HashMap$Node
对象中Map 中的 key 不允许重复,原因和HashSet一样
Map 中的 value 可以重复
Map的 key 可以为null, value 也可以为null 。但是,注意 key为 null 只能存在一个,而value 为 null 可以存在多个
常用String 类来作为 Map 的key
key 和 value 之间存在单向 一对一关系,即通过指定的key 总能找到对应的 value
2、Key-Value 示意图
3、Map接口常用方法
Mapmap=newHashMap();map.put("第一","节点1");map.put("第二","节点2");map.put("第三","节点3");map.put("第四","节点4");(1)remove : 根据键删除映射关系
map.remove("第二");(2)get :根据键获取值
Objectval=map.get("第三");(3)size : 获取元素个数
System.out.println("key-value="+map.size());(4)isEmpty : 判断个数是否为 0
System.out.println(map.isEmpty());//False(5)clear : 清除 key-value
map.clear();(6)containsKey : 查找键是否存在
System.out.println(map.containsKey("第四"));//true4、Map的遍历方式
(1)四种遍历方式
containsKey : 查找键是否存在
keySet : 获取所有的键
entrySet : 获取所有关系K-V
values : 获取所有的值
Mapmap=newHashMap();(2)keySet 遍历方式
//先取出所有的Key,通过Key取出对应的ValueSetkeyset=map.keySet();//(1)第一种方式:增强for循环for(Objectkey:keyset){System.out.println(key+"-"+map.get(key));}//(2)第二种方式:迭代器Iteratoriterator=keyset.iterator();while(iterator.hasNext()){Objectkey=iterator.next();System.out.println(key+"-"+map.get(key));}(3)values 遍历方式
//把所有的values取出Collectionvalues=map.values();//注意:这里可以使用所有的Collections使用的遍历方法//(1)取出所有的value使用增强for循环for(Objectvalue:values){System.out.println(value);}//(2)取出所有的value使用迭代器Iteratoriterator2=values.iterator();while(iterator2.hasNext()){Objectvalue=iterator2.next();System.out.println(value);}(4)entrySet 遍历方式
//通过EntrySet来获取key-valueSetentrySet=map.entrySet();//EntrySet<Map.Entry<K,V>>//(1)使用EntrySet的增强for循环遍历方式for(Objectentry:entrySet){//将entry转成Map.EntryMap.Entrym=(Map.Entry)entry;System.out.println(m.getKey()+"-"+m.getValue());}//(2)使用EntrySet的迭代器遍历方式Iteratoriterator3=entrySet.iterator();while(iterator3.hasNext()){//HashMap$Node-实现->Map.Entry(getKey,getValue)Objectentry=iterator3.next();//向下转型Map.EntryMap.Entrym=(Map.Entry)entry;System.out.println(m.getKey()+"-"+m.getValue());}
二、HashMap 类
1、注意事项
Map接口的常用实现类:HashMap、Hashtable 和 Properties
HashMap是 Map 接口使用频率最高的实现类(重点掌握)
HashMap 是以key-value 一对的方式来存储数据(HashMap$Node类型)
key 不能重复, 但是value值可以重复,二者都允许使用null键。
如果添加相同的key,则会覆盖原来的key-value,等同于修改(key不会替换,value会替换)
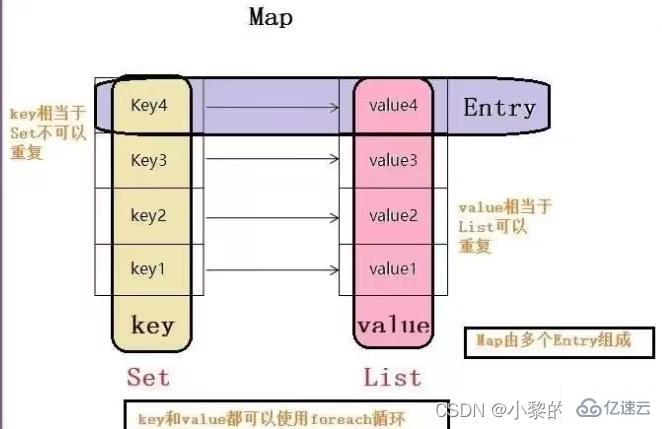
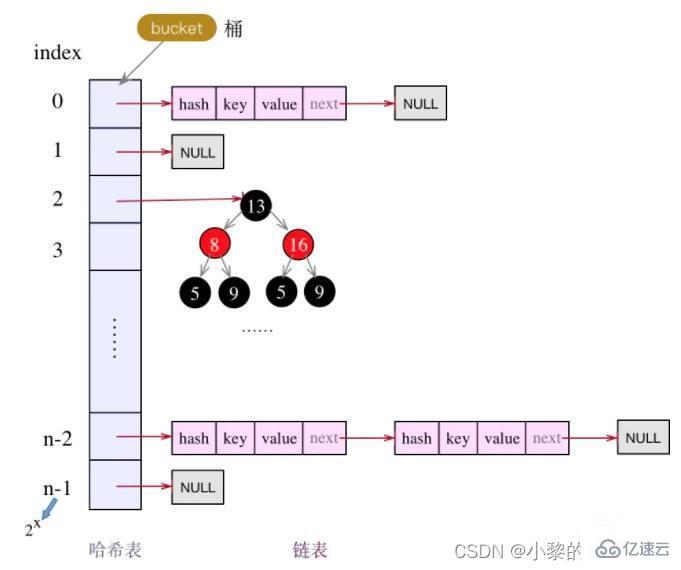
与HashSet一样, 不保证映射的顺序, 因为底层是以Hash表的方式来存储的(jdk8的HashMap 底层数组+链表+红黑树)
HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有
synchronized 关键字2、底层机制
HashMap底层维护了Node类型的数组table,默认为null
当创建对象时, 将加载因子(loadfactor)初始化为0.75
当添加key-value时,通过key的哈希值得到在table的素引。 然后判断该索引处是否有元素,如果没有元素直接添加。 如果该索引处有元素, 继续判断该元素的key和准备加入的key是否相等, 如果相等,则直接替换value; 如果不相等需要判断是树结构还是链表结构,做出相应处理。 如果添加时发现容量不够, 则需要扩容。
第1次添加, 则需要扩容table容量为16, 临界值(threshold)为12 (16*0.75)
以后再扩容, 则需要扩容table容量为原来的2倍(32). 临界值为原来的2倍,即24(32*0.75),依次类推
在Java8中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且 table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
3、底层原理图
三、HashTable 类
1、基本介绍
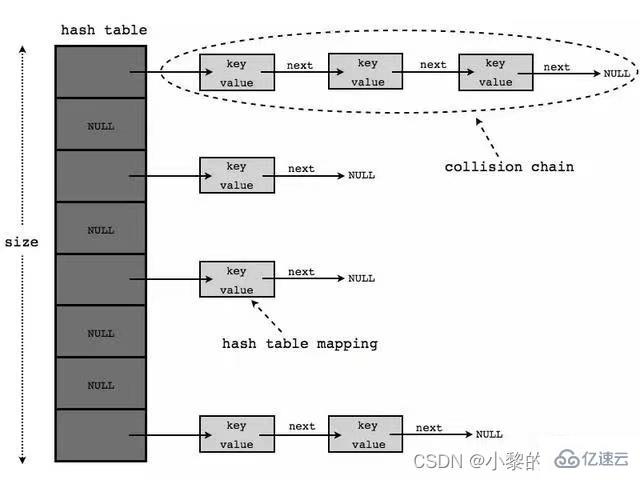
存放的元素是键值对:即Key-Value
HashTable 的键和值都不能为null
HashTable 的使用方法基本上和HashMap一样
HashTable 是线程安全的,HashMap 是线程不安全
Hashtable 和 HashMap 的比较:
2、底层结构示意图
3、HashTable 常用方法
Mapmap=newHashTable();map.put("第一","节点1");map.put("第二","节点2");map.put("第三","节点3");map.put("第四","节点4");(1)remove : 根据键删除映射关系
map.remove("第二");(2)get :根据键获取值
Objectval=map.get("第三");(3)size : 获取元素个数
System.out.println("key-value="+map.size());(4)isEmpty : 判断个数是否为 0
System.out.println(map.isEmpty());//False(5)clear : 清除 key-value
map.clear();(6)containsKey : 查找键是否存在
System.out.println(map.containsKey("第四"));//true

四、Properties 类
1、基本介绍
Properties 类继承自HashTable类并且实现了Map接口,也是使用一种键值对的形
式来保存数据。(可以通过 key-value 存放数据,当然 key 和 value 也不能为 null)它的使用特点和Hashtable类似
Properties 还可以用于从xx.properties文件中,加载数据到Properties类对象,并进行读取和修改(在IO流中会详细介绍)
2、常用方法
Propertiesproperties=newProperties();(1)put 方法
properties.put(null,"abc");//抛出空指针异常properties.put("abc",null);//抛出空指针异常properties.put("lic",100);properties.put("lic",88);//如果有相同的key,value被替换(2)get 方法
System.out.println(properties.get("lic"));(3)remove 方法
properties.remove("lic");
五、Collections 工具类
1、基本介绍
Collections 是一个操作Set. List 和 Map等集合的工具类
Collections中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作排序
2、排序操作(均为static方法)
方法 作用 reverse(List)反转 List 中元素的顺序shuffle(List)对 List集合元素进行随机排序sort(List)根据元素的自然顺序对指定List集合元素按升序排序sort(List,Comparator)根据指定的Comparator 产生的顺序对 List集合元素进行排序swap(List, int i, int j)将指定list 集合中的 i 处元素和 j 处元素进行交换Listlist=newArrayList();list.add("第一个");list.add("第二个");list.add("第三个");(1)reverse(List): 反转 List 中元素的顺序
Collections.reverse(list);(2)shuffle(List):对 List 集合元素进行随机排序
for(inti=0;i<5;i++){Collections.shuffle(list);System.out.println("list="+list);}(3)sort(List): 根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);(4)sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
//匿名内部类Collections.sort(list,newComparator(){@Overridepublicintcompare(Objecto1,Objecto2){return((String)o2).length()-((String)o1).length();}});(5)swap(List,int, int): 将指定 list 集合中的 i 处元素和 j 处元素进行交换
Collections.swap(list,0,1);.......................................................
3、查找、替换操作
方法 作用 Object max(Collection)根据元素的自然顺序,返回给定集合中的最大元素Object max(Collection, Comparator)根据 Comparator 指定的顺序,返回给定集合中的最大元素Object min(Collection)根据元素的自然顺序,返回给定集合中的最小元素Object min(Collection, Comparator)根据 Comparator 指定的顺序,返回给定集合中的最小元素int frequency(Collection, Object)返回指定集合中指定元素的出现的次数void copy(List dest,List src)将src中的内容复制到dest中boolean replaceAll(List list, Object oldVal, Object newVal)使用新值替换 List对象的所有旧值(1)Object max(Collection): 根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素="+Collections.max(list))(2)Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
//匿名内部类ObjectmaxObject=Collections.max(list,newComparator(){@Overridepublicintcompare(Objecto1,Objecto2){return((String)o1).length()-((String)o2).length();}})(3)int frequency(Collection,Object): 返回指定集合中指定元素的出现次数
System.out.println("第一个出现的次数="+Collections.frequency(list,"第一个"));(4)void copy(List dest,List src):将 src 中的内容复制到 dest 中
ArrayListdest=newArrayList();//为了完成一个完整拷贝,我们需要先给dest赋值,大小和list.size()一样for(inti=0;i<list.size();i++){dest.add("");}//拷贝Collections.copy(dest,list);(5)boolean replaceAll(List list,Object oldVal,Object newVal): 使用新值替换 List 对象的所有旧值
//如果list中,有“第一个”就替换成“0”Collections.replaceAll(list,"第一个","0");
六、总结 (必背)
1、开发中如何选择集合来使用?
(1)第一步:先判断存储的类型:是一组对象?还是一组键值对?
(2)一组对象: Collection接口
List允许重复:
增删多 : LinkedList [底层维护了一个双向链表]
改查多 : ArrayList 底层维护Object类型的可变数组]
Set不允许重复:
无序 : HashSet {底层是HashMap,维护了一个哈希表即(数组+链表+红黑树)}
排序 : TreeSet
插入和取出顺序一致 : LinkedHashSet , 维护数组+双向链表
(3)一组键值对: Map 接口
键无序 : HashMap [底层是:哈希表 jdk7:数组+链表,jdk8:数组+链表+红黑树]
键排序 : TreeMap
键插入和取出顺序一致 : LinkedHashMap读取文件 :Properties
2、HashSet 和 TreeSet分别如何实现去重的?
HashSet 的去重机制 : hashCode() + equals(),底层先通过存入对象,进行运算得到一个hash值,通过hash值得到对应的索引,如果发现table索引所在的位置没有数据, 就直接存放;如果有数据,就进行equals比较[遍历比较]。如果比较后不相同,就加入;否则就不加入。
TreeSet 的去重机制 : 如果你传入了一个Comparator 匿名对象,就使用实现的compare去重,如果方法返回0,就认为是相同的元素或数据, 就不添加;如果你没有传入一个Comparator 匿名对象,则以你添加的对象实现的Compareable接口的compareTo去重。
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">Java集合注意事项有哪些的详细内容,希望对您有所帮助,信息来源于网络。