Python Http发送请求怎么实现
导读:本文共3590.5字符,通常情况下阅读需要12分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 浅析requests在不借助其他第三方库的情况下,requests 只能发送同步请求。requests 是一个Python第三方库,处理URL资源特别方便,而且相对于urllib3来说封装了更多功能,并且使用步骤简单。我们深入一下到requests api源码来看一下:从图片来看,其实可以大概看出requests支持哪些功能 然后圈红的其实是最常用的一些功能,也... ...
目录
(为您整理了一些要点),点击可以直达。浅析requests
在不借助其他第三方库的情况下,requests 只能发送同步请求。requests 是一个Python第三方库,处理URL资源特别方便,而且相对于urllib3来说封装了更多功能,并且使用步骤简单。
我们深入一下到requests api源码来看一下:
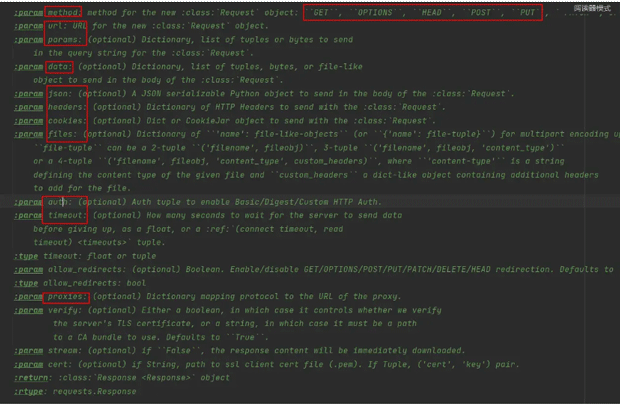
从图片来看,其实可以大概看出requests支持哪些功能 然后圈红的其实是最常用的一些功能,也就是可以设置请求方式,请求头,cookie,过期时间,请求接口验证,文件上传等等功能。
整理了日常大概常用的方,应该是下面这几种格式:
#get请求requests.get(url,params)#post请求requests.post(url,data)#文件上传upload_files={'file':open('report.xls','rb')}requests.post(url,file=upload_files)#设置headerheaders={'User-Agent':'Mozilla/5.0(iPhone;CPUiPhoneOS11_0likeMacOSX)AppleWebKit'}requests.post(url,headers=headers)#设置cookiecookies={'token':'12345','status':'摸鱼'}requests.post(url,cookies=cookies)如果单纯请求一个接口,获取接口数据的话,上面的完全够用了,不需要额外的操作。
但是requests有时候挺多用在爬虫场景下,爬虫有的需要保持登录信息去爬取其他接口,那么单纯的去使用requests.get 或者 requests.post,这都是一次性的请求,是不太满足需求的。 对于登录成功,再去请求其他的接口,可能需要之前生成的cookie或者token,这时候,这些信息就需要进行保存。对于这种情况,可以使用requests.session,它可以自动处理cookies,做状态保持.
大概的使用步骤应该是这样子:
#先实例化一个对象session=requests.session()#给requests.session()对象设置cookie信息,这个看情况使用,具体情况具体分析啊cookies_dict={}session.cookies=requests.utils.cookiejar_from_dict(cookies_dict)#后面用法和直接使用requests一样了#get请求response=session.get(url)#post请求response=session.post(url,json=json_data)result=response.json()#获取登陆的所有cookies信息print(result.cookies.values())通过上面这些大概步骤,对于信息状态保持是已经足够了,这时候再用这些保持的信息去爬取接口是没有多大问题的(按道理啊,经典案例的话可以去模拟爬取一下淘宝PC端,本文具体的就不介绍了。)
浅析aiohttp
在不借助其他第三方库的情况下,aiohttp只能发送异步请求。
其实,人都是贪心的,在同步请求足够完成需求后,那么人就会去从其他方面去提升, 比如同样的接口,希望能更快的处理返回,减少消耗时间,不希望阻塞。
那么随着这种需要,那么异步请求也就出现了。目前支持异步请求的方式有 async/await+asyncio+requests 组合构成,也可以使用aiohttp.aiohttp是一个为Python提供异步HTTP客户端、服务端编程,基于asyncio的异步库。aiohttp 同样是可以设置请求方式,请求头,cookie,代理,上传文件等功能的
大概用代码来表示,应该是常见这些:
#post请求payload={"data":"helloworld"}asyncwithaiohttp.ClientSession()assession: asyncwithsession.post(url,json=payload)asresp: print(resp.status)#get请求#创建使用sessionasyncwithaiohttp.ClientSession()assession: asyncwithsession.get(url)asresp: print(resp.status) res=awaitresp.text() returnres#上传文件files={'file':open('report.xls','rb')}asyncwithaiohttp.ClientSession()assess: asyncwithsess.post(url,data=files)asresp: print(resp.status) print(awaitresp.text())#设置header,cookieheaders={'User-Agent':'youragent'}cookies={'cookies_are':'摸鱼'}asyncwithaiohttp.ClientSession(headers=headers,cookies=cookies)assession: asyncwithsession.get(url)asresp: print(resp.status) res=awaitresp.text() returnres当然异步的请求,多可以是对接口返回数据在其他地方没有太强的依赖,异步的作用更多是用于提高效率,节省同步等待时间。
浅析httpx
在不借助其他第三方库的情况下,httpx既能发送同步请求,又能发送异步请求
httpx是Python新一代的网络请求库,它包含以下特点:
1.基于Python3的功能齐全的http请求模块
2.既能发送同步请求,也能发送异步请求
3.支持HTTP/1.1和HTTP/2
4.能够直接向WSGI应用程序或者ASGI应用程序发送请求
安装 httpx需要Python3.6+(使用异步请求需要Python3.8+)
httpx是Python新一代的网络请求库, 功能和requests基本都一致,但是requests在没有第三方库的支持下只能发同步请求, 但是httpx不仅可以发同步请求,还可以异步,这个是比requests要好的。因为和requests差不多,那么requests能支持设置的,那么httpx也同样可以支持
基本的使用方法:
data={'name':'autofelix','age':25}#get请求httpx.get(url,params=data)#post请求httpx.post(url,data=data)#设置header,cookie,timeoutheaders={'User-Agent':'youragent'}cookies={'cookies_are':'摸鱼'}httpx.get(url,headers=headers,cookies=cookies,timeout=10.0)#使用client发送(同步)请求withhttpx.Client()asclient:response=client.get(url)异步操作, 使用async/await语句来进行异步操作,使用异步client比使用多线程发送请求更加高效,更能体现明显的性能优势
importasyncioimporthttpxasyncdefmain():#异步请求AsyncClientasyncwithhttpx.AsyncClient()asclient:response=awaitclient.get(url)print(response)if__name__=='__main__':#python3.7+支持写法#asyncio.run(main())#python3.6及以下版本写法loop=asyncio.get_event_loop()result=loop.run_until_complete(asyncio.gather(main()))loop.close()
大体看下,同步请求使用httpx.client(), 异步请求使用httpx.AsyncClient(), 然后其他的一些基本用法都大体相似。可以说,如果你对requests熟练,那么对于aiohttp以及httpx也是很快就能上手理解的。
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">Python Http发送请求怎么实现的详细内容,希望对您有所帮助,信息来源于网络。