MySQL聚簇索引和非聚簇索引的区别是什么
导读:本文共1034.5字符,通常情况下阅读需要3分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 聚簇索引聚簇索引(Clustered Index)一般指的是主键索引(如果存在主键索引的话),聚簇索引也被称之为聚集索引。聚簇索引在 InnoDB 中是使用 B+ 树实现的,比如我们创建一张 student 表,它的构建 SQL 如下:droptableifexistsstudent;createtablestudent(idintprimarykey,n... ...
音频解说
目录
(为您整理了一些要点),点击可以直达。聚簇索引
聚簇索引(Clustered Index)一般指的是主键索引(如果存在主键索引的话),聚簇索引也被称之为聚集索引。
聚簇索引在 InnoDB 中是使用 B+ 树实现的,比如我们创建一张 student 表,它的构建 SQL 如下:
droptableifexistsstudent;createtablestudent(idintprimarykey,namevarchar(16),class_idintnotnull,index(class_id))engine=InnoDB;--添加测试数据insertintostudent(id,name,class_id)values(1,'张三',100),(2,'李四',200),(3,'王五',300);
以上 student 表中有一个聚簇索引(也就是主键索引)id,和一个非聚簇索引 class_id。
聚簇索引 id 对应的 B+ 树如下图所示:
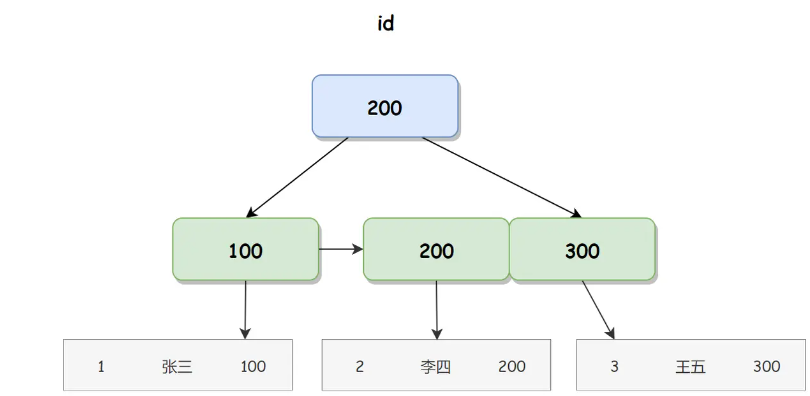
在聚簇索引的叶子节点直接存储用户信息的内存地址,我们使用内存地址可以直接找到相应的行数据。
非聚簇索引
非聚簇索引在 InnoDB 引擎中,也叫二级索引,以上面 student 表为例,
在 student 中非聚簇索引 class_id 对应 B+ 树如下图所示:
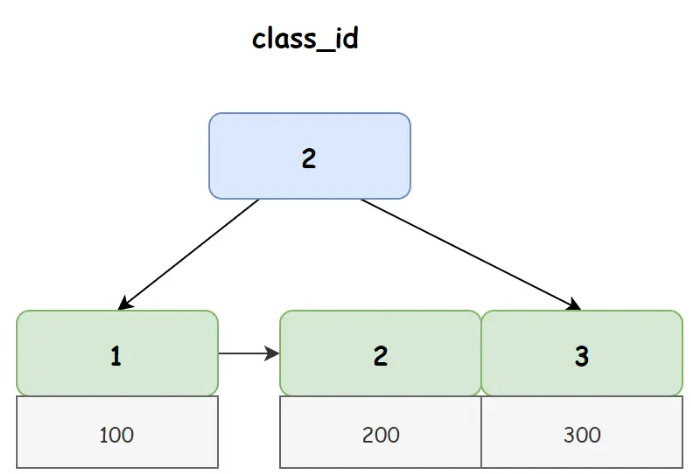
从上图我们可以看出,在非聚簇索引的叶子节点上存储的并不是真正的行数据,而是主键 ID,所以当我们使用非聚簇索引进行查询时,首先会得到一个主键 ID,然后再使用主键 ID 去聚簇索引上找到真正的行数据,我们把这个过程称之为回表查询。
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">本文:
MySQL聚簇索引和非聚簇索引的区别是什么的详细内容,希望对您有所帮助,信息来源于网络。