Python爬虫怎么实现搭建代理ip池
导读:本文共2325.5字符,通常情况下阅读需要8分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 一、User-Agent在发送请求的时候,通常都会做一个简单的反爬。这时可以用fake_useragent模块来设置一个请求头,用来进行伪装成浏览器,下面两种方法都可以。fromfake_useragentimportUserAgentheaders={#'User-Agent':UserAgent().random#常见浏览器的请求头伪装(... ...
音频解说
目录
(为您整理了一些要点),点击可以直达。一、User-Agent
在发送请求的时候,通常都会做一个简单的反爬。这时可以用fake_useragent模块来设置一个请求头,用来进行伪装成浏览器,下面两种方法都可以。
fromfake_useragentimportUserAgentheaders={#'User-Agent':UserAgent().random#常见浏览器的请求头伪装(如:火狐,谷歌)'User-Agent':UserAgent().Chrome#谷歌浏览器}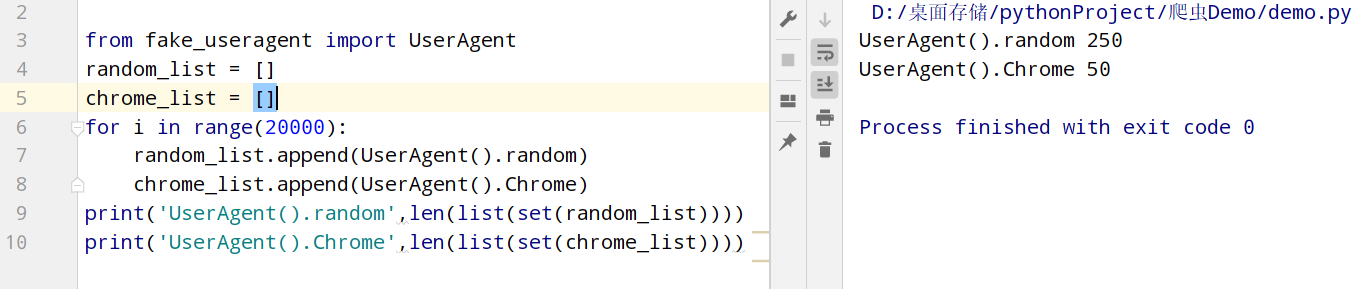
二、发送请求
response=requests.get(url='http://www.ip3366.net/free/',headers=request_header())#text=response.text.encode('ISO-8859-1')#print(text.decode('gbk'))三、解析数据
我们只需要解析出ip、port即可。
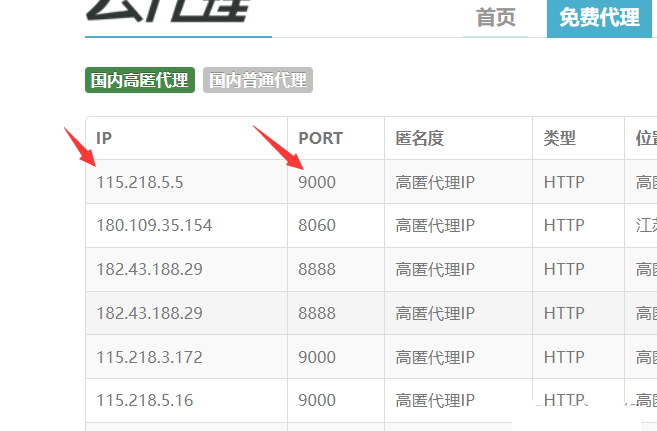
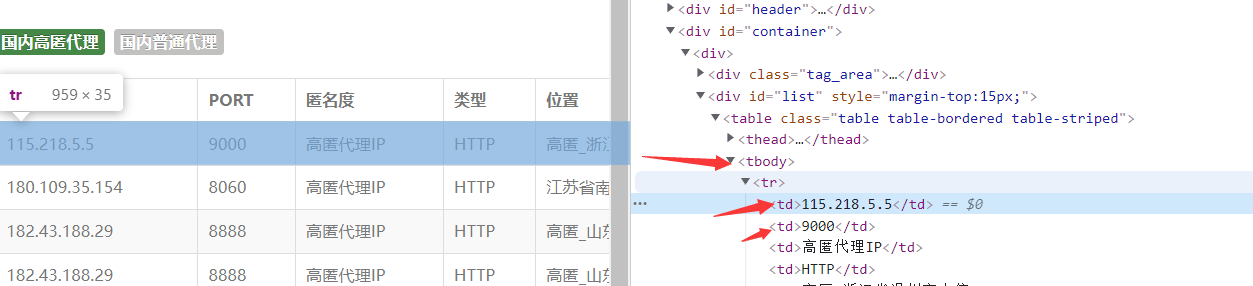
使用xpath解析(个人很喜欢用)(当然还有很多的解析方法,如:正则,css选择器,BeautifulSoup等等)。
#使用xpath解析,提取出数据ip,端口html=etree.HTML(response.text)tr_list=html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr')fortdintr_list:ip_=td.xpath('./td[1]/text()')[0]#ipport_=td.xpath('./td[2]/text()')[0]#端口proxy=ip_+':'+port_#115.218.5.5:9000四、构建ip代理池,检测ip是否可用
#构建代理ip proxy=ip+':'+port proxies={"http":"http://"+proxy,"https":"http://"+proxy,#"http":proxy,#"https":proxy,}try:response=requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1)#设置timeout,使响应等待1sresponse.close()ifresponse.status_code==200:print(proxy,'\033[31m可用\033[0m')else:print(proxy,'不可用')except:print(proxy,'请求异常')五、完整代码
importrequests#导入模块fromlxmlimportetreefromfake_useragentimportUserAgent#简单的反爬,设置一个请求头来伪装成浏览器defrequest_header():headers={#'User-Agent':UserAgent().random#常见浏览器的请求头伪装(如:火狐,谷歌)'User-Agent':UserAgent().Chrome#谷歌浏览器}returnheaders'''创建两个列表用来存放代理ip'''all_ip_list=[]#用于存放从网站上抓取到的ipusable_ip_list=[]#用于存放通过检测ip后是否可以使用#发送请求,获得响应defsend_request():#爬取7页,可自行修改foriinrange(1,8):print(f'正在抓取第{i}页……')response=requests.get(url=f'http://www.ip3366.net/free/?page={i}',headers=request_header())text=response.text.encode('ISO-8859-1')#print(text.decode('gbk'))#使用xpath解析,提取出数据ip,端口html=etree.HTML(text)tr_list=html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr')fortdintr_list:ip_=td.xpath('./td[1]/text()')[0]#ipport_=td.xpath('./td[2]/text()')[0]#端口proxy=ip_+':'+port_#115.218.5.5:9000all_ip_list.append(proxy)test_ip(proxy)#开始检测获取到的ip是否可以使用print('抓取完成!')print(f'抓取到的ip个数为:{len(all_ip_list)}')print(f'可以使用的ip个数为:{len(usable_ip_list)}')print('分别有:\n',usable_ip_list)#检测ip是否可以使用deftest_ip(proxy):#构建代理ipproxies={"http":"http://"+proxy,"https":"http://"+proxy,#"http":proxy,#"https":proxy,}try:response=requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1)#设置timeout,使响应等待1sresponse.close()ifresponse.status_code==200:usable_ip_list.append(proxy)print(proxy,'\033[31m可用\033[0m')else:print(proxy,'不可用')except:print(proxy,'请求异常')if__name__=='__main__':send_request() </div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">本文:
Python爬虫怎么实现搭建代理ip池的详细内容,希望对您有所帮助,信息来源于网络。