Python Pandas中DataFrame.drop_duplicates()怎么删除重复值
导读:本文共1538字符,通常情况下阅读需要5分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: 语法df.drop_duplicates(subset=None,keep='first',inplace=False,ignore_index=False)参数1.subset:指定的标签或标签序列,仅删除这些列重复值,默认情况为所有列2.keep:确定要保留的重复值,有以下可选项:first:保留第一次出现的重复值,默认last:保留最... ...
音频解说
目录
(为您整理了一些要点),点击可以直达。语法
df.drop_duplicates(subset=None,keep='first',inplace=False,ignore_index=False)
参数
1.subset:指定的标签或标签序列,仅删除这些列重复值,默认情况为所有列
2.keep:确定要保留的重复值,有以下可选项:
first:保留第一次出现的重复值,默认
last:保留最后一次出现的重复值
False:删除所有重复值
3.inplace:是否生效
4.ignore_index:如果为True,则重新分配自然索引(0,1,…,n - 1)
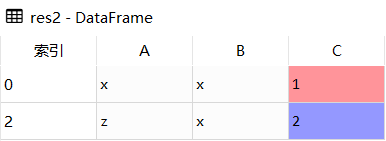
#删除重复值DataFrame.drop_duplicates()importpandasaspddf=pd.DataFrame([['x','x',1],['x','x',1],['z','x',2]],columns=['A','B','C'])#删除重复行res1=df.drop_duplicates()#删除指定列res2=df.drop_duplicates(subset=['A'])#保留最后一个res3=df.drop_duplicates(subset=['A'],keep='last')
结果展示
df
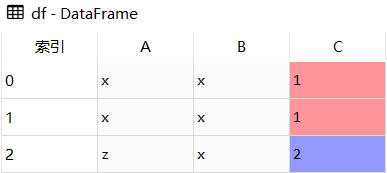
res1
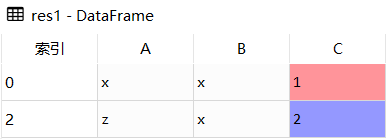
res2
res3

扩展:识别重复值
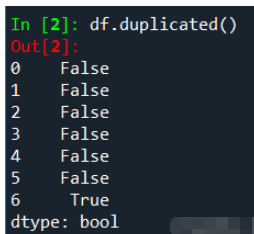
importpandasaspddf=pd.DataFrame({'studentID':['A001','A002','A003','A004','A005','A006','A006'],'score':[100,93,94,96,93,95,95]})#识别重复值duplicate_value=df[df.duplicated()]df
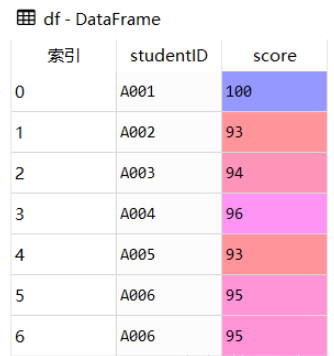
由上图可知studentID为'A006'的记录有两条,我们可以使用duplicated()方法识别重复值,它返回的是布尔值结果(True:有重复值,False:无重复值)
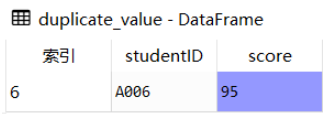
duplicate_value
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">本文:
Python Pandas中DataFrame.drop_duplicates()怎么删除重复值的详细内容,希望对您有所帮助,信息来源于网络。