Python如何实现聚类K-means算法
导读:本文共3723字符,通常情况下阅读需要12分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要: K-means(K均值)算法是最简单的一种聚类算法,它期望最小化平方误差注:为避免运行时间过长,通常设置一个最大运行轮数或最小调整幅度阈值,若到达最大轮数或调整幅度小于阈值,则停止运行。下面我们用python来实现一下K-means算法:我们先尝试手动实现这个算法,再用sklearn库中的KMeans类来实现。数据我们采用《机器学习》的西瓜数据(P202表9.1... ...
目录
(为您整理了一些要点),点击可以直达。K-means(K均值)算法是最简单的一种聚类算法,它期望最小化平方误差

注:为避免运行时间过长,通常设置一个最大运行轮数或最小调整幅度阈值,若到达最大轮数或调整幅度小于阈值,则停止运行。
下面我们用python来实现一下K-means算法:我们先尝试手动实现这个算法,再用sklearn库中的KMeans类来实现。数据我们采用《机器学习》的西瓜数据(P202表9.1):
#下面的内容保存在melons.txt中#第一列为西瓜的密度;第二列为西瓜的含糖率。我们要把这30个西瓜分为3类0.6970.4600.7740.3760.6340.2640.6080.3180.5560.2150.4030.2370.4810.1490.4370.2110.6660.0910.2430.2670.2450.0570.3430.0990.6390.1610.6570.1980.3600.3700.5930.0420.7190.1030.3590.1880.3390.2410.2820.2570.7480.2320.7140.3460.4830.3120.4780.4370.5250.3690.7510.4890.5320.4720.4730.3760.7250.4450.4460.459
手动实现
我们用到的库有matplotlib和numpy,如果没有需要先用pip安装一下。
importrandomimportnumpyasnpimportmatplotlib.pyplotasplt
下面定义一些数据:
k=3#要分的簇数rnd=0#轮次,用于控制迭代次数(见上文)ROUND_LIMIT=100#轮次的上限THRESHOLD=1e-10#单轮改变距离的阈值,若改变幅度小于该阈值,算法终止melons=[]#西瓜的列表clusters=[]#簇的列表,clusters[i]表示第i簇包含的西瓜
从melons.txt读取数据,保存在列表中:
f=open('melons.txt','r')forlineinf: #把字符串转化为numpy中的float64类型melons.append(np.array(line.split(''),dtype=np.string_).astype(np.float64))从 m m m个数据中随机挑选出 k k k个,对应上面算法的第 1 1 1行:
#random的sample函数从列表中随机挑选出k个样本(不重复)。我们在这里把这些样本作为均值向量mean_vectors=random.sample(melons,k)
下面是算法的主要部分。
#这个while对应上面算法的2-17行whileTrue:rnd+=1#轮次增加change=0#把改变幅度重置为0 #清空对簇的划分,对应上面算法的第3行clusters=[]foriinrange(k):clusters.append([])#这个for对应上面算法的4-8行formeloninmelons: ''' argmin函数找出容器中最小的下标,在这里这个目标容器是 list(map(lambdavec:np.linalg.norm(melon-vec,ord=2),mean_vectors)), 它表示melon与mean_vectors中所有向量的距离列表。 (numpy.linalg.norm计算向量的范数,ord=2即欧几里得范数,或模长) '''c=np.argmin(list(map(lambdavec:np.linalg.norm(melon-vec,ord=2),mean_vectors)))clusters[c].append(melon) #这个for对应上面算法的9-16行foriinrange(k): #求每个簇的新均值向量new_vector=np.zeros((1,2))formeloninclusters[i]:new_vector+=melonnew_vector/=len(clusters[i])#累加改变幅度并更新均值向量change+=np.linalg.norm(mean_vectors[i]-new_vector,ord=2)mean_vectors[i]=new_vector #若超过设定的轮次或者变化幅度<预先设定的阈值,结束算法ifrnd>ROUND_LIMITorchange<THRESHOLD:breakprint('最终迭代%d轮'%rnd)最后我们绘图来观察一下划分的结果:
colors=['red','green','blue']#每个簇换一下颜色,同时迭代簇和颜色两个列表fori,colinzip(range(k),colors):formeloninclusters[i]: #绘制散点图plt.scatter(melon[0],melon[1],color=col)plt.show()
划分结果(由于最开始的 k k k个均值向量随机选取,每次划分的结果可能会不同):
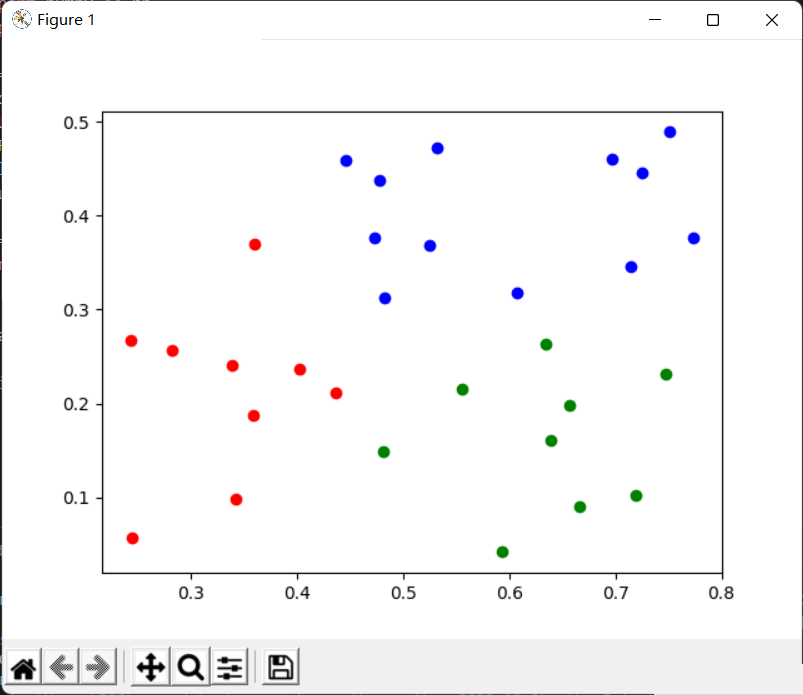
完整代码:
importrandomimportnumpyasnpimportmatplotlib.pyplotaspltk=3rnd=0ROUND_LIMIT=10THRESHOLD=1e-10melons=[]clusters=[]f=open('melons.txt','r')forlineinf:melons.append(np.array(line.split(''),dtype=np.string_).astype(np.float64))mean_vectors=random.sample(melons,k)whileTrue:rnd+=1change=0clusters=[]foriinrange(k):clusters.append([])formeloninmelons:c=np.argmin(list(map(lambdavec:np.linalg.norm(melon-vec,ord=2),mean_vectors)))clusters[c].append(melon)foriinrange(k):new_vector=np.zeros((1,2))formeloninclusters[i]:new_vector+=melonnew_vector/=len(clusters[i])change+=np.linalg.norm(mean_vectors[i]-new_vector,ord=2)mean_vectors[i]=new_vectorifrnd>ROUND_LIMITorchange<THRESHOLD:breakprint('最终迭代%d轮'%rnd)colors=['red','green','blue']fori,colinzip(range(k),colors):formeloninclusters[i]:plt.scatter(melon[0],melon[1],color=col)plt.show()sklearn库中的KMeans
这种经典算法显然不需要我们反复地造轮子,被广泛使用的python机器学习库sklearn已经提供了该算法的实现。sklearn的官方文档中给了我们一个示例:
>>>fromsklearn.clusterimportKMeans>>>importnumpyasnp>>>X=np.array([[1,2],[1,4],[1,0],...[10,2],[10,4],[10,0]])>>>kmeans=KMeans(n_clusters=2,random_state=0).fit(X)>>>kmeans.labels_array([1,1,1,0,0,0],dtype=int32)>>>kmeans.predict([[0,0],[12,3]])array([1,0],dtype=int32)>>>kmeans.cluster_centers_array([[10.,2.],[1.,2.]])
可以看出,X即要聚类的数据(1,2),(1,4),(1,0)等。KMeans类的初始化参数n_clusters即簇数 k k k;random_state是用于初始化选取 k k k个向量的随机数种子;kmeans.labels_即每个点所属的簇;kmeans.predict方法预测新的数据属于哪个簇;kmeans.cluster_centers_返回每个簇的中心。
我们就改造一下这个简单的示例,完成对上面西瓜的聚类。
importnumpyasnpimportmatplotlib.pyplotaspltfromsklearn.clusterimportKMeansX=[]f=open('melons.txt','r')forlineinf:X.append(np.array(line.split(''),dtype=np.string_).astype(np.float64))kmeans=KMeans(n_clusters=3,random_state=0).fit(X)colors=['red','green','blue']fori,clusterinenumerate(kmeans.labels_):plt.scatter(X[i][0],X[i][1],color=colors[cluster])plt.show()运行结果如下,可以看到和我们手写的聚类结果基本一致:
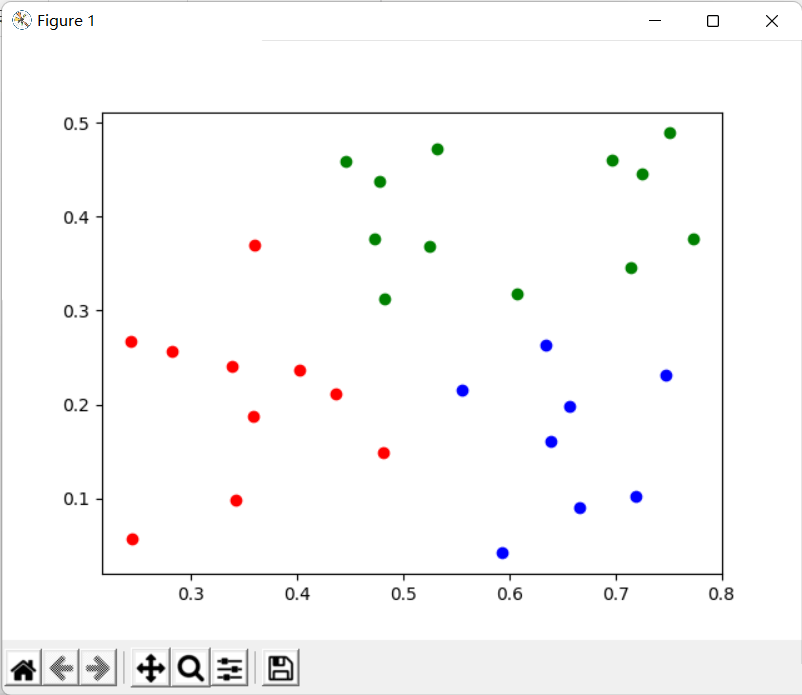
</div> <div class="zixun-tj-product adv-bottom"></div> </div> </div> <div class="prve-next-news">Python如何实现聚类K-means算法的详细内容,希望对您有所帮助,信息来源于网络。