C++简易版Tensor如何实现
导读:本文共10363字符,通常情况下阅读需要35分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要:基础知识铺垫缺省参数异常处理如果有模板元编程经验更好std::memset、std::fill、std::fill_n、std::memcpystd::memset 的内存填充单位固定为字节(char),所以不能应用与double,非char类型只适合置0。std::fill 和 std::fill_n 则可以对指定类型进行内存填充,更加通用。std::memcpy 则可以讲内存中排列好的数据拷贝... ...
目录
(为您整理了一些要点),点击可以直达。基础知识铺垫
缺省参数
异常处理
如果有模板元编程经验更好
std::memset、std::fill、std::fill_n、std::memcpy
std::memset 的内存填充单位固定为字节(char),所以不能应用与double,非char类型只适合置0。
std::fill 和 std::fill_n 则可以对指定类型进行内存填充,更加通用。
std::memcpy 则可以讲内存中排列好的数据拷贝过去,不同位置可填充不同值。
doubledp[505];
std::memset(dp,-1.0,505sizeof(double));//错误的★★★,memset的单位是字节(char),我们需要的是fill
doubledp[505];
std::fill(dp,dp+505,-1.0);
std::fill(std::begin(dp),std::end(dp),-1.0);
std::fill_n(dp,505,-1.0);
doubledp[505];
doubledata[5]={11,22,33,44,55};
std::memcpy(dp,data,5sizeof(double))
内存管理 allocate
在c++11中引入了智能指针这个概念,这个非常好,但是有一个问题显然被忘记了,如何动态创建智能指针数组,在c++11中没有提供直接的函数。换句话说,创建智能指针的make_shared,不支持创建数组。那在c++11中如何创建一个智能指针数组呢?只能自己封装或者变通实现,在c++14后可以支持构造函数创建智能指针数组,可这仍然不太符合技术规范发展的一致性,可继承性。
共享指针share_ptr 和 唯一指针unique_ptr 可能并不是一个很完整的方式,因为默认情况下需要开发人员手动的指定 delete handler。 但是只需要简单的封装一下就可以是更智能的方式,就是自动生成 delete handler。并且不必使用new(或者其他的指针形式)作为构造参数,而是直接通过 allocate 和 construct 两种形式,最抽象简单直观的方式得到想要的。
shared_ptr<T>pt0(newT());//将会自动采用std::default_delete
shared_ptr<int>p1=make_shared<int>();
//指定default_delete作为释放规则
std::shared_ptr<int>p6(newint[10],std::default_delete<int[]>());
//自定义释放规则
voiddeleteInt(int*p){delete[]p;}
std::shared_ptr<int>p3(newint[10],deleteInt);
我们期待的规范后是这样使用的:不用考虑 释放规则,而且分为 allocate 和 construct 两种形式。
autouptr=Alloc::unique_allocate<Foo>(sizeof(Foo));
autosptr=Alloc::shared_allocate<Foo>(sizeof(Foo));
autouptr=Alloc::unique_construct<Foo>();
autosptr=Alloc::shared_construct<Foo>('6','7');
allocator.h
#ifndefUTILS_ALLOCATOR_HdefineUTILS_ALLOCATOR_H
include<cstdlib>
include<map>
include<memory>
include<utility>
include"base_config.h"
namespacest{
//工具类(单例)
classAlloc{
public:
//allocate删除器
classtrivial_delete_handler{
public:
trivial_delete_handler(indextsize):size(size_){}
voidoperator()(voidptr){deallocate(ptr,size);}
private:
index_tsize;
};
//construct删除器
template<typenameT>
classnontrivial_delete_handler{
public:
voidoperator()(voidptr){
static_cast<T>(ptr)->~T();
deallocate(ptr,sizeof(T));
}
};
//unique_ptr:对应allocate
template<typenameT>
usingTrivialUniquePtr=std::unique_ptr<T,trivial_delete_handler>;
//unique_ptr:对应construct
template<typenameT>
usingNontrivialUniquePtr=std::unique_ptr<T,nontrivial_delete_handler<T>>;
//Iknowit'sweirdhere.ThetypehasbeenalreadypassedinasT,butthe
//functionparameterstillneedthenumberofbytes,insteadofobjects.
//Andtheirrelationshipis
//nbytes=nobjectssizeof(T).
//CheckwhatIdoin"tensor/storage.cpp",andyou'llunderstand.
//Ormaybechangingtheparameterhereanddoingsomeextraworkin
//"tensor/storage.cpp"isbetter.
//共享指针allocate
//目的:自动生成deletehandler
template<typenameT>
staticstd::shared_ptr<T>shared_allocate(index_tnbytes){
voidraw_ptr=allocate(nbytes);
returnstd::shared_ptr<T>(
static_cast<T>(raw_ptr),
trivial_delete_handler(nbytes)
);
}
//唯一指针allocate
//目的:自动生成deletehandler
template<typenameT>
staticTrivialUniquePtr<T>unique_allocate(index_tnbytes){
//开辟内存
voidraw_ptr=allocate(nbytes);
//返回unique_ptr(自动生成了删除器)
returnTrivialUniquePtr<T>(
static_cast<T>(raw_ptr),
trivial_delete_handler(nbytes)
);
}
//共享指针construct
//目的:自动生成deletehandler
template<typenameT,typename...Args>
staticstd::shared_ptr<T>shared_construct(Args&&...args){
voidraw_ptr=allocate(sizeof(T));
new(raw_ptr)T(std::forward<Args>(args)...);
returnstd::shared_ptr<T>(
static_cast<T>(raw_ptr),
nontrivial_delete_handler<T>()
);
}
//唯一指针construct
//目的:自动生成deletehandler
template<typenameT,typename...Args>
staticNontrivialUniquePtr<T>unique_construct(Args&&...args){
voidraw_ptr=allocate(sizeof(T));
new(raw_ptr)T(std::forward<Args>(args)...);
returnNontrivialUniquePtr<T>(
static_cast<T>(raw_ptr),
nontrivial_delete_handler<T>()
);
}
staticboolallclear(void);
private:
Alloc()=default;
~Alloc(){
/releaseuniqueptr,themapwillnotdodestruction!!!/
for(autoiter=cache.begin();iter!=cache_.end();++iter){iter->second.release();}
}
staticAlloc&self();//单例
staticvoidallocate(index_tsize);
staticvoiddeallocate(voidptr,index_tsize);
staticindex_tallocate_memory_size;
staticindex_tdeallocate_memory_size;
structfree_deletor{
voidoperator()(void*ptr){std::free(ptr);}
};
//multimap允许容器有重复的key值
//保留开辟过又释放掉的堆内存,再次使用的时候可重复使用(省略了查找可用堆内存的操作)
std::multimap<index_t,std::unique_ptr<void,freedeletor>>cache;
};
}//namespacestendif
allocator.cpp
#include"allocator.h"include"exception.h"
include<iostream>
namespacest{
index_tAlloc::allocate_memory_size=0;
index_tAlloc::deallocate_memory_size=0;
Alloc&Alloc::self(){
staticAllocalloc;
returnalloc;
}
voidAlloc::allocate(indextsize){
autoiter=self().cache.find(size);
voidres;
if(iter!=self().cache.end()){
//临时:为什么要这么做?找到了为社么要删除
res=iter->second.release();//释放指针指向内存
self().cache.erase(iter);//擦除
}else{
res=std::malloc(size);
CHECK_NOT_NULL(res,"failedtoallocate%dmemory.",size);
}
allocate_memory_size+=size;
returnres;
}
voidAlloc::deallocate(voidptr,index_tsize){
deallocate_memorysize+=size;
//本质上是保留保留堆内存中的位置,下一次可直接使用,而不是重新开辟
self().cache.emplace(size,ptr);//插入
}
boolAlloc::all_clear(){
returnallocate_memory_size==deallocate_memory_size;
}
}//namespacest
使用:封装成 unique_allocate、unique_construct、share_allocate、share_construct 的目的就是对 share_ptr 和 unique_ptr 的生成自动赋予其对应的 delete handler。
structFoo{
staticintctr_call_counter;
staticintdectr_callcounter;
charx;
chary_;
Foo(){++ctr_callcounter;}
Foo(charx,chary):x(x),y_(y){++ctr_call_counter;}
~Foo(){++dectr_call_counter;}
};
intFoo::ctr_call_counter=0;
intFoo::dectr_call_counter=0;
voidtest_Alloc(){
usingnamespacest;
//allocate开辟空间
//construct开辟空间+赋值
voidptr;
{//
autouptr=Alloc::unique_allocate<Foo>(sizeof(Foo));
CHECK_EQUAL(Foo::ctr_call_counter,0,"check1");
ptr=uptr.get();
}
CHECK_EQUAL(Foo::dectr_call_counter,0,"check1");
{
autosptr=Alloc::shared_allocate<Foo>(sizeof(Foo));
//Thestrategyofallocator.
CHECK_EQUAL(ptr,static_cast<void>(sptr.get()),"check2");
}
{
autouptr=Alloc::unique_construct<Foo>();
CHECK_EQUAL(Foo::ctr_call_counter,1,"check3");
CHECK_EQUAL(ptr,static_cast<void>(uptr.get()),"check3");
}
CHECK_EQUAL(Foo::dectr_call_counter,1,"check3");
{
autosptr=Alloc::shared_construct<Foo>('6','7');
CHECK_EQUAL(Foo::ctr_call_counter,2,"check4");
CHECKTRUE(sptr->x=='6'&&sptr->y_=='7',"check4");
CHECK_EQUAL(ptr,static_cast<void*>(sptr.get()),"check4");
}
CHECK_EQUAL(Foo::dectr_call_counter,2,"check4");
}实现Tensor需要准备shape和storage
shape 管理形状,每一个Tensor的形状都是唯一的(采用 unique_ptr管理数据),见array.h 个 shape.h。
storage:管理数据,不同的Tensor的数据可能是同一份数据(share_ptr管理数据),见stroage.h。
array.h
#ifndefUTILS_ARRAY_HdefineUTILS_ARRAY_H
include<initializer_list>
include<memory>
include<cstring>
include<iostream>
//utils
include"base_config.h"
include"allocator.h"
namespacest{
//应用是tensor的shape,shape是唯一的,所以用unique_ptr
//临时:实际上并不是很完善,目前的样子有点对不起这个Dynamic单词
template<typenameDtype>
classDynamicArray{
public:
explicitDynamicArray(indextsize)
:size(size),
dptr_(Alloc::uniqueallocate<Dtype>(sizesizeof(Dtype))){
}
DynamicArray(std::initializerlist<Dtype>data)
:DynamicArray(data.size()){
autoptr=dptr.get();
for(autod:data){
ptr=d;
++ptr;
}
}
DynamicArray(constDynamicArray<Dtype>&other)
:DynamicArray(other.size()){
std::memcpy(dptr.get(),other.dptr.get(),size_sizeof(Dtype));
}
DynamicArray(constDtypedata,indextsize)
:DynamicArray(size){
std::memcpy(dptr.get(),data,size_sizeof(Dtype));
}
explicitDynamicArray(DynamicArray<Dtype>&&other)=default;
~DynamicArray()=default;
Dtype&operator{returndptr_.get()[idx];}
Dtypeoperatorconst{returndptr_.get()[idx];}
indextsize()const{returnsize;}
//注意std::memset的单位是字节(char),若不是char类型,只用来置0,否则结果错误
//临时:std::memset对非char类型只适合内存置0,如果想要更加通用,不妨考虑一下std::fill和std::filln
voidmemset(intvalue)const{std::memset(dptr.get(),value,size_sizeof(Dtype));}//原
voidfill(intvalue)const(std::filln,size,value);//改:见名知意
private:
indextsize;
Alloc::TrivialUniquePtr<Dtype>dptr_;
};
}//namespacestendif
stroage.h
#ifndefTENSOR_STORAGE_HdefineTENSOR_STORAGE_H
include<memory>
include"base_config.h"
include"allocator.h"
namespacest{
namespacenn{
classInitializerBase;
classOptimizerBase;
}
classStorage{
public:
explicitStorage(index_tsize);
Storage(constStorage&other,index_toffset);//观察:offset具体应用?bptr_数据依然是同一份,只是dptr_指向位置不同,这是关于pytorch的clip,切片等操作的设计方法
Storage(index_tsize,data_tvalue);
Storage(constdata_tdata,index_tsize);
explicitStorage(constStorage&other)=default;//复制构造(因为数据都是指针形式,所以直接默认就行)
explicitStorage(Storage&&other)=default;//移动构造(因为数据都是指针形式,所以直接默认就行)
~Storage()=default;
Storage&operator=(constStorage&other)=delete;
//inlinefunction
data_toperatorconst{returndptr_[idx];}
data_t&operator{returndptr_[idx];}
indextoffset(void)const{returndptr-bptr->data;}//
indextversion(void)const{returnbptr->version_;}//
voidincrementversion(void)const{++bptr->version_;}//???
//friendfunction
friendclassnn::InitializerBase;
friendclassnn::OptimizerBase;
public:
indextsize;
private:
structVdata{
indextversion;//???
datatdata[1];//永远指向数据头
};
std::sharedptr<Vdata>bptr;//basepointer,share_ptr的原因是不同的tensor可能指向的是storage数据
data_tdptr;//datapointer,指向Vdata中的data,他是移动的(游标)
};
}//namespacestendif
storage.cpp
#include<iostream>include<cstring>
include<algorithm>
include"storage.h"
namespacest{
Storage::Storage(indextsize)
:bptr(Alloc::shared_allocate<Vdata>(sizesizeof(data_t)+sizeof(indext))),
dptr(bptr->data)
{
bptr->version=0;
this->size_=size;
}
Storage::Storage(constStorage&other,indextoffset)
:bptr(other.bptr),
dptr(other.dptr+offset)
{
this->size=other.size_;
}
Storage::Storage(index_tsize,datatvalue)
:Storage(size){
//std::memset(dptr,value,sizesizeof(data_t));//临时
std::filln(dptr,size,value);
}
Storage::Storage(constdata_tdata,indextsize)
:Storage(size){
std::memcpy(dptr,data,sizesizeof(data_t));
}
}//namespacest
shape.h
#ifndefTENSOR_SHAPE_HdefineTENSOR_SHAPE_H
include<initializer_list>
include<ostream>
include"base_config.h"
include"allocator.h"
include"array.h"
namespacest{
classShape{
public:
//constructor
Shape(std::initializer_list<index_t>dims);
Shape(constShape&other,index_tskip);
Shape(index_t*dims,index_tdim);
Shape(IndexArray&&shape);
Shape(constShape&other)=default;
Shape(Shape&&other)=default;
~Shape()=default;
//method
index_tdsize()const;
index_tsubsize(index_tstart_dim,index_tend_dim)const;
index_tsubsize(index_tstart_dim)const;
booloperator==(constShape&other)const;
//inlinefunction
indextndim(void)const{returndims.size();}
index_toperatorconst{returndims_[idx];}
index_t&operator{returndims[idx];}
operatorconstIndexArray()const{returndims;}
//friendfunction
friendstd::ostream&operator<<(std::ostream&out,constShape&s);
private:
IndexArraydims_;//IndexArray就是(DynamicArray)
};
}//namespacestendif
shape.cpp
#include"shape.h"namespacest{
Shape::Shape(std::initializer_list<indext>dims):dims(dims){}
Shape::Shape(constShape&other,indextskip):dims(other.ndim()-1){
inti=0;
for(;i<skip;++i)
dims[i]=other.dims[i];
for(;i<dims.size();++i)
dims[i]=other.dims_[i+1];
}
Shape::Shape(index_tdims,indextdim):dims(dims,dim){}
Shape::Shape(IndexArray&&shape):dims_(std::move(shape)){}
indextShape::dsize()const{
intres=1;
for(inti=0;i<dims.size();++i)
res=dims_[i];
returnres;
}
index_tShape::subsize(index_tstart_dim,index_tend_dim)const{
intres=1;
for(;start_dim<end_dim;++startdim)
res*=dims[start_dim];
returnres;
}
index_tShape::subsize(index_tstart_dim)const{
returnsubsize(startdim,dims.size());
}
boolShape::operator==(constShape&other)const{
if(this->ndim()!=other.ndim())returnfalse;
indexti=0;
for(;i<dims.size()&&dims[i]==other.dims[i];++i)
;
returni==dims.size();
}
std::ostream&operator<<(std::ostream&out,constShape&s){
out<<'('<<s[0];
for(inti=1;i<s.ndim();++i)
out<<","<<s[i];
out<<")";
returnout;
}
}//namespacest
Tensor的设计方法(基础)
知识准备:继承、指针类、奇异递归模板(静态多态)、表达式模板、Impl设计模式(声明实现分离)、友元类、模板特化。
tensor的设计采用的 impl 方法(声明和实现分离), 采用了奇异递归模板(静态多态),Tensor本身管理Tensor的张量运算,Exp则管理引用计数、梯度计数(反向求导,梯度更新时需要用到)的运算。
一共5个类:Tensor,TensorImpl,Exp,ExpImpl,ExpImplPtr,他们之间的关系由下图体现。
先上图:
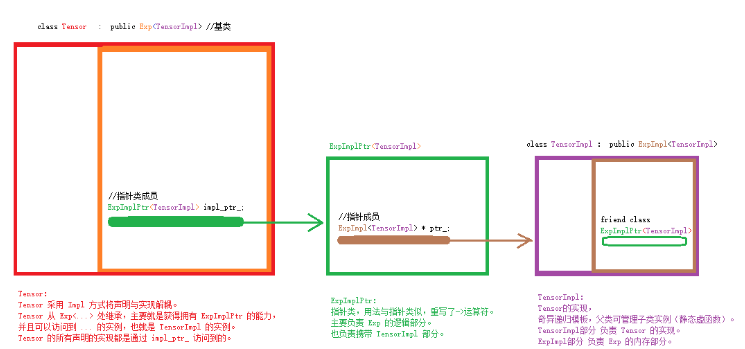
代码:
//代码比较多,就不放在这了,参看源码结合注释理解
Tensor的设计方法(更进一步)
Tensor 数据内存分布管理
Tensor的数据只有独一份,那么Tensor的各种操作 transpose,purmute,slice,等等,难道都要生出一个新的 tensor 和对应新的数据吗?当然不可能,能用一份数据的绝不用两份!tensor 数据的描述主要有 size(总数数据量),offset(此 tensor 相对于原始base数据的一个偏移量) ndim(几个维度),shape(每个维度映射的个数),stride(每个维度中数据的索引步长),stride 和 shape是 一 一 对应的,通过这个stride的索引公式,我们就可以用一份数据幻化出不同的tensor表象了。解析如下图

permute(轴换位置):shape 和 stride 调换序列一致即可。
transpose(指定两个轴换位置,转置):同上,与permute一致。
slice(切片):在原始数据上增加了一个偏移量。Tensor中的数据部分Storage中有一个bptr(管理原始数据)和dptr_(管理当前tensor的数据指向)。
unsqueese(升维):指定dim加一个维度,且shape值为1,stride值则根据shape的subsize(dim)算出即可。
squeese(降维):dim为1的将自动消失并降维,shape 和 stride 对应位子都会去掉。
view(变形):目前是只支持连续数据分布且数据的size总和不变的情况,比如permute、transpose就会破坏这种连续。slice就会破坏数据size不一致。
C++简易版Tensor如何实现的详细内容,希望对您有所帮助,信息来源于网络。