C++如何实现xml解析器
导读:本文共7475字符,通常情况下阅读需要25分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要:接下来,请跟着小编一起来学习吧!xml格式简单介绍<?xmlversion="1.0"?><!--这是注释--><workflow><workname="1"switch="on"><pluginname="echoplugin.so"switch=&quo... ...
目录
(为您整理了一些要点),点击可以直达。接下来,请跟着小编一起来学习吧!
xml格式简单介绍
<?xmlversion="1.0"?>
<!--这是注释-->
<workflow>
<workname="1"switch="on">
<pluginname="echoplugin.so"switch="on"/>
</work>
</workflow>
我们来简单观察下上面的xml文件,xml格式和html格式十分类似,一般用于存储需要属性的配置或者需要多个嵌套关系的配置。
xml一般使用于项目的配置文件,相比于其他的ini格式或者yaml格式,它的优势在于可以将一个标签拥有多个属性,比如上述xml文件格式是用于配置工作流的,其中有name属性和switch属性,且再work标签中又嵌套了plugin标签,相比较其他配置文件格式是要灵活很多的。
具体的应用场景有很多,比如使用过Java中Mybatis的同学应该清楚,Mybatis的配置文件就是xml格式,而且也可以通过xml格式进行sql语句的编写,同样Java的maven项目的配置文件也是采用的xml文件进行配置。
而我为什么要写一个xml解析器呢?很明显,我今后要写的C++项目需要用到。
xml格式解析过程浅析
同样回到之前的那段代码,实际上已经把xml文件格式的不同情况都列出来了。
从整体上看,所有的xml标签分为:
xml声明(包含版本、编码等信息)
注释
xml元素:1.单标签元素。 2.成对标签元素。
其中xml声明和注释都是非必须的。 而xml元素,至少需要一个成对标签元素,而且在最外层有且只能有一个,它作为根元素。
从xml元素来看,分为:
名称
属性
内容
子节点
根据之前的例子,很明显,名称是必须要有的而且是唯一的,其他内容则是可选。 根据元素的结束形式,我们把他们分为单标签和双标签元素。
代码实现
完整代码仓库:xml-parser
实现存储解析数据的类——Element
代码如下:
namespacexml
{
usingstd::vector;
usingstd::map;
usingstd::string_view;
usingstd::string;
classElement
{
public:
usingchildren_t=vector<Element>;
usingattrs_t=map<string,string>;
usingiterator=vector<Element>::iterator;
usingconst_iterator=vector<Element>::const_iterator;
string&Name()
{
returnm_name;
}
string&Text()
{
returnm_text;
}
//迭代器方便遍历子节点
iteratorbegin()
{
returnm_children.begin();
}
[[nodiscard]]const_iteratorbegin()const
{
returnm_children.begin();
}
iteratorend()
{
returnm_children.end();
}
[[nodiscard]]const_iteratorend()const
{
returnm_children.end();
}
voidpush_back(Elementconst&element)//方便子节点的存入
{
m_children.push_back(element);
}
string&operator//方便key-value的存取
{
returnm_attrs[key];
}
stringto_string()
{
return_to_string();
}
private:
string_to_string();
private:
stringm_name;
stringm_text;
children_tm_children;
attrs_tm_attrs;
};
}
上述代码,我们主要看成员变量。
我们用string类型表示元素的name和text
用vector嵌套表示孩子节点
用map表示key-value对的属性
其余的方法要么是Getter/Setter,要么是方便操作孩子节点和属性。 当然还有一个to_string()方法这个待会讲。
关键代码1——实现整体的解析
关于整体结构我们分解为下面的情形:
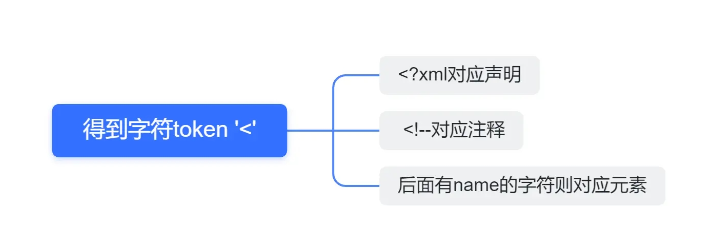
代码如下:
Elementxml::Parser::Parse()
{
while(true)
{
chart=_get_next_token();
if(t!='<')
{
THROW_ERROR("invalidformat",m_str.substr(m_idx,detail_len));
}
//解析版本号
if(m_idx+4<m_str.size()&&m_str.compare(m_idx,5,"<?xml")==0)
{
if(!_parse_version())
{
THROW_ERROR("versionparseerror",m_str.substr(m_idx,detail_len));
}
continue;
}
//解析注释
if(m_idx+3<m_str.size()&&m_str.compare(m_idx,4,"<!--")==0)
{
if(!_parse_comment())
{
THROW_ERROR("commentparseerror",m_str.substr(m_idx,detail_len));
}
continue;
}
//解析element
if(m_idx+1<m_str.size()&&(isalpha(m_str[m_idx+1])||m_str[midx+1]==''))
{
return_parse_element();
}
//出现未定义情况直接抛出异常
THROW_ERROR("errorformat",m_str.substr(m_idx,detail_len));
}
}
上述代码我们用while循环进行嵌套的原因在于注释可能有多个。
关键代码2——解析所有元素
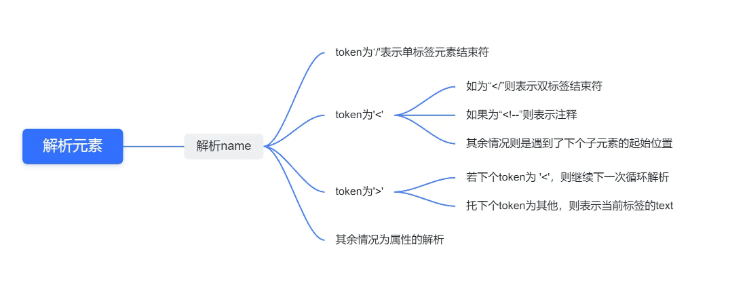
对应代码:
Elementxml::Parser::_parse_element()
{
Elementelement;
autopre_pos=++m_idx;//过掉<
//判断name首字符合法性
if(!(m_idx<m_str.size()&&(std::isalpha(m_str[m_idx])||m_str[midx]=='')))
{
THROW_ERROR("erroroccurinparsename",m_str.substr(m_idx,detail_len));
}
//解析name
while(m_idx<m_str.size()&&(isalpha(m_str[m_idx])||m_str[m_idx]==':'||
m_str[m_idx]=='-'||m_str[midx]==''||m_str[m_idx]=='.'))
{
m_idx++;
}
if(m_idx>=m_str.size())
THROW_ERROR("erroroccurinparsename",m_str.substr(m_idx,detail_len));
element.Name()=m_str.substr(pre_pos,m_idx-pre_pos);
//正式解析内部
while(m_idx<m_str.size())
{
chartoken=_get_next_token();
if(token=='/')//1.单元素,直接解析后结束
{
if(m_str[m_idx+1]=='>')
{
m_idx+=2;
returnelement;
}else
{
THROW_ERROR("parsesingle_elementfailed",m_str.substr(m_idx,detail_len));
}
}
if(token=='<')//2.对应三种情况:结束符、注释、下个子节点
{
//结束符
if(m_str[m_idx+1]=='/')
{
if(m_str.compare(m_idx+2,element.Name().size(),element.Name())!=0)
{
THROW_ERROR("parseendtagerror",m_str.substr(m_idx,detail_len));
}
m_idx+=2+element.Name().size();
charx=_get_next_token();
if(x!='>')
{
THROW_ERROR("parseendtagerror",m_str.substr(m_idx,detail_len));
}
m_idx++;//千万注意把'>'过掉,防止下次解析被识别为初始的tag结束,实际上这个element已经解析完成
returnelement;
}
//是注释的情况
if(m_idx+3<m_str.size()&&m_str.compare(m_idx,4,"<!--")==0)
{
if(!_parse_comment())
{
THROW_ERROR("parsecommenterror",m_str.substr(m_idx,detail_len));
}
continue;
}
//其余情况可能是注释或子元素,直接调用parse进行解析得到即可
element.push_back(Parse());
continue;
}
if(token=='>')//3.对应两种情况:该标签的text内容,下个标签的开始或者注释(直接continue跳到到下次循环即可
{
m_idx++;
//判断下个token是否为text,如果不是则continue
charx=_get_next_token();
if(x=='<')//不可能是结束符,因为xml元素不能为空body,如果直接出现这种情况也有可能是中间夹杂了注释
{
continue;
}
//解析text再解析child
autopos=m_str.find('<',m_idx);
if(pos==string::npos)
THROW_ERROR("parsetexterror",m_str.substr(m_idx,detail_len));
element.Text()=m_str.substr(m_idx,pos-m_idx);
m_idx=pos;
//注意:有可能直接碰上结束符,所以需要continue,让element里的逻辑来进行判断
continue;
}
//4.其余情况都为属性的解析
autokey=_parse_attr_key();
autox=_get_next_token();
if(x!='=')
{
THROW_ERROR("parseattrserror",m_str.substr(m_idx,detail_len));
}
m_idx++;
autovalue=_parse_attr_value();
element[key]=value;
}
THROW_ERROR("parseelementerror",m_str.substr(m_idx,detail_len));
}
开发技巧
无论是C++开发,还是各种其他语言的造轮子,在这个造轮子的过程中,不可能是一帆风顺的,需要不断的debug,然后再测试,然后再debug。。。实际上这类格式的解析,单纯的进行程序的调试效率是非常低下的!
特别是你用的语言还是C++,那么如果出现意外宕机行为,debug几乎是不可能简单的找出原因的,所以为了方便调试,或者是意外宕机行为,我们还是多做一些错误、异常处理的工作比较好。
比如上述的代码中,我们大量的用到了 THROW_ERROR 这个宏,实际上这个宏输出的内容是有便于调试和快速定位的。 具体代码如下:
//用于返回较为详细的错误信息,方便错误追踪defineTHROW_ERROR(error_info,error_detail)\
do{\
stringinfo="parseerrorin";\
stringfile_pos=FILE;\
file_pos.append(":");\
file_pos.append(std::to_string(LINE));\
info+=file_pos;\
info+=",";\
info+=(error_info);\
info+="\ndetail:";\
info+=(error_detail);\
throwstd::logic_error(info);\
}while(false)
如果发生错误,这个异常携带的信息如下:

打印出了两个非常关键的信息:
内部的C++代码解析抛出异常的位置
解析发生错误的字符串
按理来说这些信息应该是用日志来进行记录的,但是由于这个项目比较小型,直接用日常信息当日志来方便调试也未尝不可????
有关C++的优化
众所周知在C++中,一个类有八个默认函数:
默认构造函数
默认拷贝构造函数
默认析构函数
默认重载赋值运算符函数
默认重载取址运算符函数
默认重载取址运算符const函数
默认移动构造函数(C++11)
默认重载移动赋值操作符函数(C++11)
我们一般情况需要注意的构造函数和赋值函数函数需要的是以下三类:
拷贝构造。
移动构造。
析构函数。
以下面的代码为例来说明默认的行为:
classData{
...
}
classtest{
pvivate:
Datam_data;
}额外注意
默认情况的模拟
classData{
...
}
classtest{
public:
//拷贝构造
test(testconst&src)=default;//等价于下面的代码
//test(testconst&src):m_data(src.m_data){}
//移动构造
test(test&&src)=default;//等价于下面代码
//tset(test&&src):m_data(std::move(src.m_data)){}
pvivate:
Datam_data;
}从上述情况可以看出,如果一个类的数据成员中含有原始指针数据,那么拷贝构造和移动构造都需要自定义,如果成员中全都用的标准库里的东西,那么我们就用默认的就行,因为标准库的所有成员都自己实现了拷贝和移动构造!比如我们目前的Element就全都用默认的就好。
需要特别注意的点
显式定义了某个构造函数或者赋值函数,那么相应的另一个构造或者赋值就会被删除默认,需要再次显式定义了。 举个例子:比如我显式定义了移动构造(关于显式定义,手动创建算显式,手动写default也算显示),那么就会造成所有的默认拷贝(拷贝构造和拷贝赋值)被删除。相反显式定义了移动赋值也是类似的,默认的拷贝行为被删除。拷贝的对于显式的默认行为处理也是一模一样。
如果想要使用默认的构造/赋值函数,那么对应的成员也都必须支持。 例如以下代码:
classData{
...
}
classtest{
pvivate:
Datam_data;
}由于test类没有写任何构造函数,那么这8个默认构造函数按理来说都是有的,但如果Data类中的拷贝构造由于某些显式定义情况而被删除了,那么test类就不再支持拷贝构造(对我们造成的影响就是:没法再直接通过等号初始化)。
最后,通过上述规则我们发现,如果想要通过默认的构造函数偷懒,那么首先你的成员得支持对应的构造函数,还有就是不要画蛇添足:比如本来我什么都不用写,它自动生成8大默认函数,然后你手写了一个拷贝构造=default,好了,你的默认函数从此少了两个,又得你一个个手动去补了!
故如果成员变量对移动和拷贝行为都是支持的,那么你就千万不要再画蛇添足了,除非你需要自定义某些特殊行为(比如打日志什么的)。如果你的成员变量中含有原始指针,那么一定需要手动写好移动和拷贝行为。如果成员变量对拷贝和移动行为部分支持,那么根据你的使用情况来进行选择是否需要手动补充这些行为!
若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!C++如何实现xml解析器的详细内容,希望对您有所帮助,信息来源于网络。