Python多线程是什么及怎么用
导读:本文共10124字符,通常情况下阅读需要34分钟。同时您也可以点击右侧朗读,来听本文内容。按键盘←(左) →(右) 方向键可以翻页。
摘要:希望大家仔细阅读,能够学有所成!什么是线程?你为什么想要它?从本质上讲,Python是一种线性语言,但当你需要更多的处理能力时,线程模块非常方便。虽然Python中的线程不能用于并行CPU计算,但它非常适合I/O操作,如web抓取,因为处理器处于空闲状态,等待数据。线程正在改变游戏规则,因为许多与网络/数据I/O相关的脚本将大部分时间用于等待来自远程源的数据。由于下载可能没有链接(即,抓取单独的网... ...
目录
(为您整理了一些要点),点击可以直达。希望大家仔细阅读,能够学有所成!
什么是线程?你为什么想要它?
从本质上讲,Python是一种线性语言,但当你需要更多的处理能力时,线程模块非常方便。虽然Python中的线程不能用于并行CPU计算,但它非常适合I/O操作,如web抓取,因为处理器处于空闲状态,等待数据。
线程正在改变游戏规则,因为许多与网络/数据I/O相关的脚本将大部分时间用于等待来自远程源的数据。由于下载可能没有链接(即,抓取单独的网站),处理器可以并行地从不同的数据源下载,并在最后合并结果。对于CPU密集型进程,使用线程模块没有什么好处。
幸运的是,线程包含在标准库中:
importthreading
fromqueueimportQueue
importtime
你可以使用target作为可调用对象,使用args将参数传递给函数,并start启动线程。
deftestThread(num):
printnumifname=='main':
foriinrange(5):
t=threading.Thread(target=testThread,arg=(i,))
t.start()
如果你以前从未见过if name == 'main':,这基本上是一种确保嵌套在其中的代码仅在脚本直接运行(而不是导入)时运行的方法。
锁
同一操作系统进程的线程将计算工作负载分布到多个内核中,如C++和Java等编程语言所示。通常,python只使用一个进程,从该进程生成一个主线程来执行运行时。由于一种称为全局解释器锁(global interpreter lock)的锁定机制,它保持在单个核上,而不管计算机有多少核,也不管产生了多少新线程,这种机制是为了防止所谓的竞争条件。
提到竞争,我想到了想到 NASCAR 和一级方程式赛车。让我们用这个类比,想象所有一级方程式赛车手都试图同时在一辆赛车上比赛。听起来很荒谬,对吧?,这只有在每个司机都可以使用自己的车的情况下才有可能,或者最好还是一次跑一圈,每次把车交给下一个司机。
这与线程中发生的情况非常相似。线程是从“主”线程“派生”的,每个后续线程都是前一个线程的副本。这些线程都存在于同一进程“上下文”(事件或竞争)中,因此分配给该进程的所有资源(如内存)都是共享的。例如,在典型的python解释器会话中:
>>>a=8
在这里,a通过让内存中的某个任意位置暂时保持值 8 来消耗很少的内存 (RAM)。
到目前为止一切顺利,让我们启动一些线程并观察它们的行为,当添加两个数字x时y:
importtime
importthreading
fromthreadingimportThreada=8
defthreaded_add(x,y):
simulationofamorecomplextaskbyasking
pythontosleep,sinceaddinghappenssoquick!
foriinrange(2):
globala
print("computingtaskinadifferentthread!")
time.sleep(1)thisisnotokay!butpythonwillforcesync,moreonthatlater!
a=10
print(a)thecurrentthreadwillbeasubsetfork!
ifname!="main":
current_thread=threading.current_thread()herewetellpythonfromthemain
threadofexecutionmakeothers
ifname=="main":
thread=Thread(target=threaded_add,args=(1,2))
thread.start()
thread.join()
print(a)
print("mainthreadfinished...exiting")
>>>computingtaskinadifferentthread!
>>>10
>>>computingtaskinadifferentthread!
>>>10
>>>10
>>>mainthreadfinished...exiting
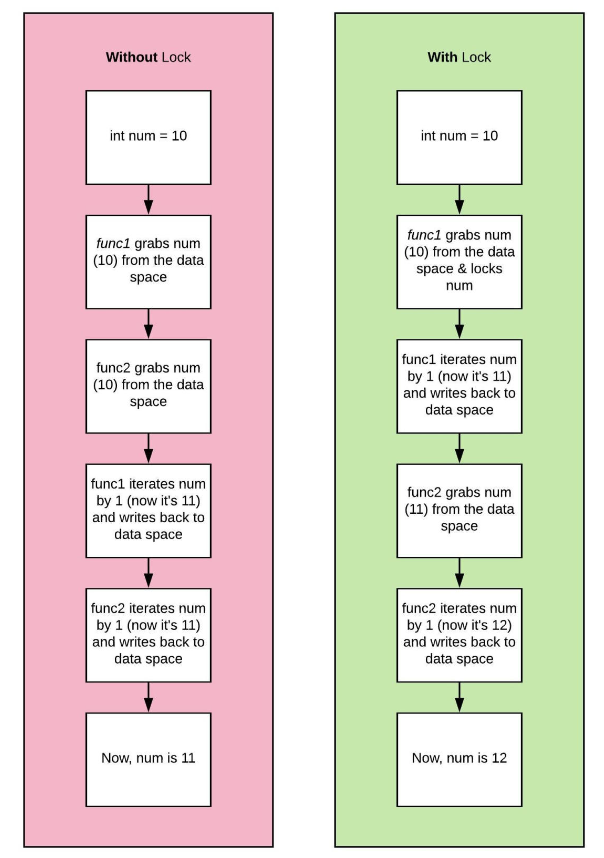
两个线程当前正在运行。让我们把它们称为thread_one和thread_two。如果thread_one想要用值10修改a,而thread_two同时尝试更新同一变量,我们就有问题了!将出现称为数据竞争的情况,并且a的结果值将不一致。
一场你没有看的赛车比赛,但从你的两个朋友那里听到了两个相互矛盾的结果!thread_one告诉你一件事,thread two反驳了这一点!这里有一个伪代码片段说明:
a=8spawnstwodifferentthreads1and2
thread_oneupdatesthevalueofato10
if(a==10):
acheck
thread_twoupdatesthevalueofato15
a=15
b=a*2ifthread_onefinishedfirsttheresultwillbe20
ifthread_twofinishedfirsttheresultwillbe30
whoisright?
到底是怎么回事?
Python是一种解释语言,这意味着它带有一个解释器——一个从另一种语言解析其源代码的程序!python中的一些此类解释器包括cpython、pypypy、Jpython和IronPython,其中,cpython是python的原始实现。
CPython是一个解释器,它提供与C以及其他编程语言的外部函数接口,它将python源代码编译成中间字节码,由CPython虚拟机进行解释。迄今为止和未来的讨论都是关于CPython和理解环境中的行为。
内存模型和锁定机制
编程语言使用程序中的对象来执行操作。这些对象由基本数据类型组成,如string、integer或boolean。它们还包括更复杂的数据结构,如list或classes/objects。程序对象的值存储在内存中,以便快速访问。在程序中使用变量时,进程将从内存中读取值并对其进行操作。在早期的编程语言中,大多数开发人员负责他们程序中的所有内存管理。这意味着在创建列表或对象之前,首先必须为变量分配内存。在这样做时,你可以继续释放以“释放”内存。
在python中,对象通过引用存储在内存中。引用是对象的一种标签,因此一个对象可以有许多名称,比如你如何拥有给定的名称和昵称。引用是对象的精确内存位置。引用计数器用于python中的垃圾收集,这是一种自动内存管理过程。
在引用计数器的帮助下,python通过在创建或引用对象时递增引用计数器和在取消引用对象时递减来跟踪每个对象。当引用计数为0时,对象的内存将被释放。
importsysimportgc
hello="world"#referenceto'world'is2
print(sys.getrefcount(hello))bye="world"
other_bye=bye
print(sys.getrefcount(bye))
print(gc.get_referrers(other_bye))
>>>4
>>>6
>>>[['sys','gc','hello','world','print','sys','getrefcount','hello','bye','world','other_bye','bye','print','sys','getrefcount','bye','print','gc','get_referrers','other_bye'],(0,None,'world'),{'name':'main','doc':None,'package':None,'loader':<_frozen_importlib_external.SourceFileLoaderobjectat0x0138ADF0>,'spec':None,'annotations':{},'builtins':<module'builtins'(built-in)>,'file':'test.py','cached':None,'sys':<module'sys'(built-in)>,'gc':<module'gc'(built-in)>,'hello':'world','bye':'world','other_bye':'world'}]
需要保护这些参考计数器变量,防止竞争条件或内存泄漏。以保护这些变量;可以将锁添加到跨线程共享的所有数据结构中。
CPython 的 GIL 通过一次允许一个线程控制解释器来控制 Python 解释器。它为单线程程序提供了性能提升,因为只需要管理一个锁,但代价是它阻止了多线程 CPython 程序在某些情况下充分利用多处理器系统。
当用户编写python程序时,性能受CPU限制的程序和受I/O限制的程序之间存在差异。CPU通过同时执行许多操作将程序推到极限,而I/O程序必须花费时间等待I/O。
因此,只有多线程程序在GIL中花费大量时间来解释CPython字节码;GIL成为瓶颈。即使没有严格必要,GIL也会降低性能。例如,一个用python编写的同时处理IO和CPU任务的程序:
importtime,os
fromthreadingimportThread,current_thread
frommultiprocessingimportcurrent_processCOUNT=200000000
SLEEP=10defio_bound(sec):
pid=os.getpid()
threadName=current_thread().name
processName=current_process().name
print(f"{pid}{processName}{threadName}\
--->Startsleeping...")
time.sleep(sec)
print(f"{pid}{processName}{threadName}\
--->Finishedsleeping...")defcpu_bound(n):
pid=os.getpid()
threadName=current_thread().name
processName=current_process().name
print(f"{pid}{processName}{threadName}\
--->Startcounting...")
whilen>0:
n-=1
print(f"{pid}{processName}{threadName}\
--->Finishedcounting...")deftimeit(function,args,threaded=False):
start=time.time()
ifthreaded:
t1=Thread(target=function,args=(args,))
t2=Thread(target=function,args=(args,))
t1.start()
t2.start()
t1.join()
t2.join()
else:
function(args)
end=time.time()
print('Timetakeninsecondsforrunning{}onArgument{}is{}s-{}'.format(function,args,end-start,"Threaded"ifthreadedelse"NoneThreaded"))ifname=="main":
Runningio_boundtask
print("IOBOUNDTASKNONTHREADED")
timeit(io_bound,SLEEP)print("IOBOUNDTASKTHREADED")
Runningio_boundtaskinThread
timeit(io_bound,SLEEP,threaded=True)
print("CPUBOUNDTASKNONTHREADED")
Runningcpu_boundtask
timeit(cpu_bound,COUNT)
print("CPUBOUNDTASKTHREADED")
Runningcpu_boundtaskinThread
timeit(cpu_bound,COUNT,threaded=True)
>>>IOBOUNDTASKNONTHREADED
>>>17244MainProcessMainThread--->Startsleeping...
>>>17244MainProcessMainThread--->Finishedsleeping...
>>>17244MainProcessMainThread--->Startsleeping...
>>>17244MainProcessMainThread--->Finishedsleeping...
>>>Timetakeninsecondsforrunning<functionio_boundat0x00C50810>onArgument10is20.036664724349976s-NoneThreaded
>>>IOBOUNDTASKTHREADED
>>>10180MainProcessThread-1--->Startsleeping...
>>>10180MainProcessThread-2--->Startsleeping...
>>>10180MainProcessThread-1--->Finishedsleeping...
>>>10180MainProcessThread-2--->Finishedsleeping...
>>>Timetakeninsecondsforrunning<functionio_boundat0x01B90810>onArgument10is10.01464056968689s-Threaded
>>>CPUBOUNDTASKNONTHREADED
>>>14172MainProcessMainThread--->Startcounting...
>>>14172MainProcessMainThread--->Finishedcounting...
>>>14172MainProcessMainThread--->Startcounting...
>>>14172MainProcessMainThread--->Finishedcounting...
>>>Timetakeninsecondsforrunning<functioncpu_boundat0x018F4468>onArgument200000000is44.90199875831604s-NoneThreaded
>>>CPUBOUNDTASKTHEADED
>>>15616MainProcessThread-1--->Startcounting...
>>>15616MainProcessThread-2--->Startcounting...
>>>15616MainProcessThread-1--->Finishedcounting...
>>>15616MainProcessThread-2--->Finishedcounting...
>>>Timetakeninsecondsforrunning<functioncpu_boundat0x01E44468>onArgument200000000is106.09711360931396s-Threaded
从结果中我们注意到,multithreading在多个IO绑定任务中表现出色,执行时间为10秒,而非线程方法执行时间为20秒。我们使用相同的方法执行CPU密集型任务。好吧,最初它确实同时启动了我们的线程,但最后,我们看到整个程序的执行需要大约106秒!然后发生了什么?这是因为当Thread-1启动时,它获取全局解释器锁(GIL),这防止Thread-2使用CPU。因此,Thread-2必须等待Thread-1完成其任务并释放锁,以便它可以获取锁并执行其任务。锁的获取和释放增加了总执行时间的开销。因此,可以肯定地说,线程不是依赖CPU执行任务的理想解决方案。
这种特性使并发编程变得困难。如果GIL在并发性方面阻碍了我们,我们是不是应该摆脱它,还是能够关闭它?。嗯,这并不容易。其他功能、库和包都依赖于GIL,因此必须有一些东西来取代它,否则整个生态系统将崩溃。这是一个很难解决的问题。
多进程
我们已经证实,CPython使用锁来保护数据不受竞速的影响,尽管这种锁存在,但程序员已经找到了一种显式实现并发的方法。当涉及到GIL时,我们可以使用multiprocessing库来绕过全局锁。多处理实现了真正意义上的并发,因为它在不同CPU核上跨不同进程执行代码。它创建了一个新的Python解释器实例,在每个内核上运行。不同的进程位于不同的内存位置,因此它们之间的对象共享并不容易。在这个实现中,python为每个要运行的进程提供了不同的解释器;因此在这种情况下,为多处理中的每个进程提供单个线程。
importos
importtime
frommultiprocessingimportProcess,current_processSLEEP=10
COUNT=200000000defcount_down(cnt):
pid=os.getpid()
processName=current_process().name
print(f"{pid}*{processName}\
--->Startcounting...")
whilecnt>0:
cnt-=1defio_bound(sec):
pid=os.getpid()
threadName=current_thread().name
processName=current_process().name
print(f"{pid}{processName}{threadName}\
--->Startsleeping...")
time.sleep(sec)
print(f"{pid}{processName}{threadName}\
--->Finishedsleeping...")ifname=='main':
creatingprocesses
start=time.time()
CPUBOUND
p1=Process(target=count_down,args=(COUNT,))
p2=Process(target=count_down,args=(COUNT,))IOBOUND
p1=Process(target=,args=(SLEEP,))
p2=Process(target=count_down,args=(SLEEP,))
startingprocess_thread
p1.start()
p2.start()waituntilfinished
p1.join()
p2.join()stop=time.time()
elapsed=stop-startprint("Thetimetakeninsecondsis:",elapsed)
>>>1660Process-2--->Startcounting...
>>>10184Process-1--->Startcounting...
>>>Thetimetakeninsecondsis:12.815475225448608
可以看出,对于cpu和io绑定任务,multiprocessing性能异常出色。MainProcess启动了两个子进程,Process-1和Process-2,它们具有不同的PIDs,每个都执行将COUNT减少到零的任务。每个进程并行运行,使用单独的CPU内核和自己的Python解释器实例,因此整个程序执行只需12秒。
请注意,输出可能以无序的方式打印,因为过程彼此独立。这是因为每个进程都在自己的默认主线程中执行函数。
我们还可以使用asyncio库(上一节我已经讲过了,没看的可以返回到上一节去学习)绕过GIL锁。asyncio的基本概念是,一个称为事件循环的python对象控制每个任务的运行方式和时间。事件循环知道每个任务及其状态。就绪状态表示任务已准备好运行,等待阶段表示任务正在等待某个外部任务完成。在异步IO中,任务永远不会放弃控制,也不会在执行过程中被中断,因此对象共享是线程安全的。
importtime
importasyncioCOUNT=200000000
asynchronousfunctiondefination
asyncdeffunc_name(cnt):
whilecnt>0:
cnt-=1asynchronousmainfunctiondefination
asyncdefmain():
Creating2tasks.....Youcouldcreateasmanytasks(ntasks)
task1=loop.create_task(func_name(COUNT))
task2=loop.create_task(func_name(COUNT))awaiteachtasktoexecutebeforehandingcontrolbacktotheprogram
awaitasyncio.wait([task1,task2])
ifname=='main':
gettheeventloop
start_time=time.time()
loop=asyncio.get_event_loop()runalltasksintheeventloopuntilcompletion
loop.run_until_complete(main())
loop.close()
print("---%sseconds---"%(time.time()-start_time))
>>>---41.74118399620056seconds---
我们可以看到,asyncio需要41秒来完成倒计时,这比multithreading的106秒要好,但对于cpu受限的任务,不如multiprocessing的12秒。Asyncio创建一个eventloop和两个任务task1和task2,然后将这些任务放在eventloop上。然后,程序await任务的执行,因为事件循环执行所有任务直至完成。
为了充分利用python中并发的全部功能,我们还可以使用不同的解释器。JPython和IronPython没有GIL,这意味着用户可以充分利用多处理器系统。
与线程一样,多进程仍然存在缺点:
数据在进程之间混洗会产生 I/O 开销
整个内存被复制到每个子进程中,这对于更重要的程序来说可能是很多开销
Python多线程是什么及怎么用的详细内容,希望对您有所帮助,信息来源于网络。